1. 평가 개요
목적 한국어 법령 및 조례 검색(RAG) 시스템에 최적화된 임베딩 모델 선정
평가 데이터셋
- KCL-MCQA (Korean Canonical Legal Benchmark)
- 282개 질문, 867개 판례 (전문가 태깅 Ground Truth)
평가 데이터 선정 이유
- 현재 한국어 법령/조례에 대한 공개 벤치마크 데이터셋이 부재
- KCL-MCQA는 법률 도메인에서 검증된 유일한 한국어 검색 평가 데이터셋
- 판례와 법령/조례는 동일한 법률 용어 및 문체를 공유하여 유사한 임베딩 성능 예상
- 향후 법령/조례 특화 평가 데이터셋 구축 시 재평가 권장
평가 환경
- 검색 엔진: PostgreSQL pgvector with HNSW index
- 평가 지표: Recall@5, Precision@5, MRR, NDCG@5
2. 비교 모델
| 모델 | Provider | Dimension | 특징 |
|---|---|---|---|
| Amazon Titan V2 | AWS Bedrock | 1024 | AWS 네이티브, 저비용 |
| Cohere Embed V4 | AWS Bedrock | 1536 | 다국어 특화, 고성능 |
| KURE-v1 | HuggingFace (SageMaker 서빙 필요) | 1024 | 한국어 특화 오픈소스 |
3. 평가 지표 설명
Recall@K (재현율) ⭐⭐⭐
정의: 실제 관련 문서 중 상위 K개 결과에 포함된 비율
계산식: (상위 K개에서 찾은 관련 문서 수) / (전체 관련 문서 수)
해석
- 높을수록 관련 문서를 빠짐없이 잘 찾음
- 법률 검색에서 가장 중요한 지표 (누락 방지)
예시: 관련 판례가 5건인데 상위 5개 결과에 3건이 포함됨 → Recall@5 = 60%
Precision@K (정밀도) ⭐
정의: 상위 K개 결과 중 실제 관련 문서의 비율
계산식: (상위 K개에서 찾은 관련 문서 수) / K
해석
- 높을수록 검색 결과에 불필요한 문서가 적음
- 사용자가 확인해야 할 문서 수를 줄여줌
예시: 상위 5개 결과 중 3건이 실제 관련 문서 → Precision@5 = 60%
MRR (Mean Reciprocal Rank, 평균 역순위) ⭐⭐
정의: 첫 번째 관련 문서가 나타난 순위의 역수 평균
계산식: 1 / (첫 번째 관련 문서의 순위)
해석
- 높을수록 관련 문서가 상위에 빨리 등장
- 사용자가 첫 번째로 보는 결과의 품질 측정
예시
- 첫 번째 결과가 관련 문서 → MRR = 1.0
- 세 번째 결과가 첫 관련 문서 → MRR = 0.33
NDCG@K (Normalized Discounted Cumulative Gain) ⭐⭐
정의: 순위를 고려한 검색 품질 종합 점수
해석
- 관련 문서가 상위에 있을수록 높은 점수
- 단순히 “있다/없다"가 아닌 “어디에 있는가"를 평가
- 0~1 사이 값, 1에 가까울수록 이상적인 순위
예시: 관련 문서가 1, 2위에 있으면 높은 점수, 8, 9위에 있으면 낮은 점수
4. 평가 결과
4.1 성능 지표 비교
| 모델 | Recall@5 | Precision@5 | MRR | NDCG@5 | 순위 |
|---|---|---|---|---|---|
| Cohere Embed V4 | 55.60% | 34.54% | 69.45% | 55.14% | 1위 |
| KURE-v1 | 47.15% | 29.36% | 63.57% | 47.02% | 2위 |
| Amazon Titan V2 | 40.09% | 24.18% | 59.00% | 40.68% | 3위 |
4.2 성능 비교 차트
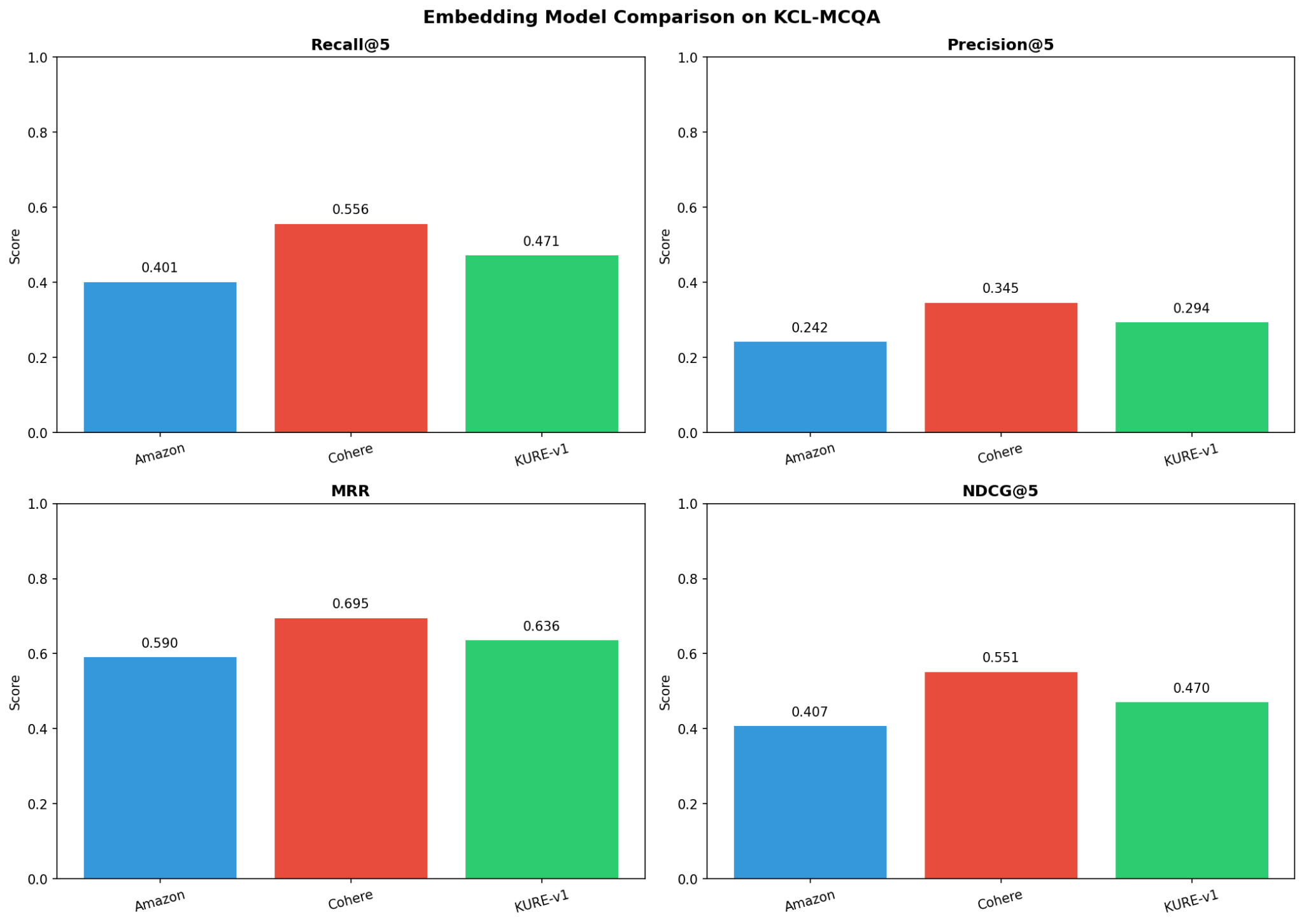
그림: 세 모델의 성능 지표 비교
4.3 성능 차이 분석
| 비교 | Recall 차이 | 향상률 | MRR 차이 | 향상률 |
|---|---|---|---|---|
| Cohere vs Titan | +15.5%p | 38.7% | +10.5%p | 17.7% |
| Cohere vs KURE | +8.5%p | 17.9% | +5.9%p | 9.3% |
| KURE vs Titan | +7.1%p | 17.6% | +4.6%p | 7.7% |
4.4 핵심 발견
- Cohere Embed V4가 모든 지표에서 1위
- 한국어 특화 KURE-v1이 범용 Titan V2보다 우수하나, Cohere에는 미치지 못함
- MRR 차이가 Recall보다 작음 → 모든 모델이 “첫 번째 결과"는 비교적 잘 찾음
5. 비용 분석
5.1 임베딩 API 비용 (Bedrock)
| 모델 | 가격 (1K tokens) | 1,000문서 비용 | 100만 문서 비용 |
|---|---|---|---|
| Amazon Titan V2 | $0.00002 | $0.012 | $12.30 |
| Cohere Embed V4 | $0.00012 | $0.060 | $60.00 |
5.2 KURE-v1 서빙 비용 (SageMaker)
KURE-v1은 오픈소스이지만 서빙을 위해 SageMaker 인프라가 필요합니다.
| 서빙 방식 | 메모리/인스턴스 | 시간당 비용 | 월 10만 요청 | 비고 |
|---|---|---|---|---|
| Serverless | 4GB | ~$0.0000467/초 | $5-10 | 가변비용 |
| Real-time | ml.g4dn.xlarge | ~$0.7364/시간 | $530 | 고정비용 |
5.3 월간 운영 비용 비교 (10만 요청 기준)
| 모델 | 서빙 방식 | 월 비용 | 관리 부담 |
|---|---|---|---|
| Titan V2 | Bedrock API | ~$1.23 | 없음 |
| Cohere V4 | Bedrock API | ~$6.00 | 없음 |
| KURE-v1 | SageMaker Serverless | ~$5-10 | 중간 (콜드 스타트) |
| KURE-v1 | SageMaker Real-time | ~$50-100 | 높음 (인스턴스 관리) |
6. 모델별 상세 분석
6.1 Cohere Embed V4
| 구분 | 내용 |
|---|---|
| 강점 | - 최고 성능 (Recall 55.6%) - 다국어 학습으로 한국어 법률 용어 이해도 높음 - Bedrock 통합으로 운영 간편 |
| 약점 | - Titan 대비 약 5배 높은 비용 |
| 적합한 경우 | 법률 서비스, 정확성이 중요한 B2B 서비스 |
6.2 KURE-v1 (Korea University)
| 구분 | 내용 |
|---|---|
| 강점 | - 한국어 특화 학습 - 오픈소스로 커스터마이징 가능 - 1024 dim으로 저장 효율적 |
| 약점 | - SageMaker 서빙 필요 (추가 인프라 관리) - Serverless 콜드 스타트 지연 (수 초) - Real-time 엔드포인트는 비용 부담 - Cohere 대비 성능 8.5%p 낮음 |
| 적합한 경우 | 파인튜닝/커스터마이징 필요 시, 내부 시스템 (지연 허용 가능) |
6.3 Amazon Titan V2
| 구분 | 내용 |
|---|---|
| 강점 | - 가장 저렴한 비용 - Bedrock 네이티브 통합 - 운영 복잡도 최소 |
| 약점 | - 가장 낮은 성능 (Recall 40.1%) - 한국어 법률 도메인 최적화 부족 |
| 적합한 경우 | MVP/프로토타입, 비용 민감 서비스, 정확성보다 속도/비용 중요 |
7. 권장 사항
7.1 최종 권장
Cohere Embed V4
법률 도메인에서 15%p의 Recall 차이는 비용 차이보다 훨씬 중요합니다.
7.2 권장 이유
- 법률 도메인 특수성
관련 법령/조례 누락은 잘못된 법률 해석으로 이어질 수 있습니다.
- Recall 55.6% vs 40.1% = 10건 중 1.5건 추가 발견
- 이 1.5건이 핵심 조문일 수 있음
- 비용의 상대적 의미
| 항목 | 비용 |
|---|---|
| Cohere 추가 비용 (월 10만 요청) | $4.77 |
| 법률 서비스 1건 수임료 | 수백만 원~ |
→ ROI 관점에서 Cohere 비용은 미미함
- 운영 편의성
- Bedrock API로 인프라 관리 불필요
- KURE-v1 대비 SageMaker 운영 부담 없음
8. 결론
성능 순위
| 순위 | 모델 | Recall@5 | 특징 |
|---|---|---|---|
| 1 | Cohere Embed V4 | 55.6% | 최고 성능 |
| 2 | KURE-v1 | 47.2% | 한국어 특화 |
| 3 | Amazon Titan V2 | 40.1% | 저비용 |
핵심 인사이트
| 관점 | 결론 |
|---|---|
| 절대 성능 | Cohere V4가 모든 지표에서 우수 |
| 비용 효율 | Titan V2가 가장 효율적이나 성능 희생 큼 |
| 한국어 특화 | KURE-v1이 Titan보다 우수하나 Cohere에 미치지 못함 |
| 운영 편의성 | Bedrock 모델(Titan, Cohere)이 SageMaker보다 간편 |
최종 결론
법률 도메인의 핵심 가치는 “신뢰성"입니다.
Cohere V4의 55.6% Recall은 완벽하지 않지만, Titan V2의 40.1%나 KURE-v1의 47.2%보다 훨씬 신뢰할 수 있습니다.
법령/조례 검색에서 “찾지 못한 조문"으로 인한 리스크는 월 몇 달러의 비용 절감으로 상쇄할 수 없습니다.
따라서 Cohere Embed V4를 권장합니다.
부록: 평가 환경
| 항목 | 내용 |
|---|---|
| 평가 일자 | 2025년 1월 |
| 데이터셋 | KCL-MCQA (lbox/kcl) |
| 평가 쿼리 | 282개 |
| 코퍼스 | 867개 판례 (500자 이상) |
| 검색 엔진 | PostgreSQL 16 + pgvector 0.7 |
| 인덱스 | HNSW (m=16, ef_construction=64) |
