
가상화 기반 Edge 배포 · Pub/Sub Payload 한계 우회 · 멱등성 기반 정합성 확보
파일럿 현장의 돌발 변수와 클라우드 한계를 극복한 MDE 최적화 과정
Cloud Tech Unit · GCP Delivery SA 3 윤성재 | 2026-02-23
문제 정의 — 진흙탕 속의 엔지니어링
아키텍처 설계도가 아무리 완벽해도, 제조 현장의 랙 마운트 서버와 네트워크 케이블 앞에서는 무용지물이 되곤 합니다. 지난 글에서 ‘우아한’ 아키텍처를 다뤘다면, 이번에는 파일럿 기간 동안 현장 엔지니어들이 온몸으로 부딪혀야 했던 진흙탕 같은 트러블슈팅 과정을 다룹니다.
이 글에서는 파일럿 운영 보고서에 기록된 치열했던 문제 해결 과정 3가지를 가감 없이 공유합니다.
Challenge 1: 하드웨어 호환성과 엣지 배포의 악몽
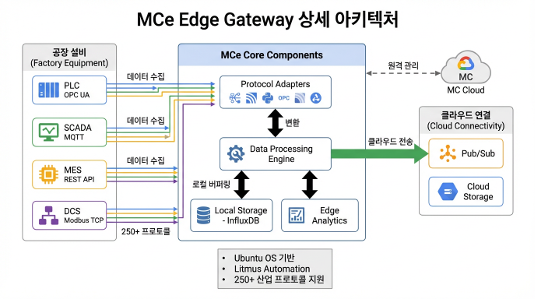
베어메탈 다중 디스크(RAID) 볼륨 구성의 제약
공장 현장에 배치된 Dell 물리 서버(Baremetal)에 엣지 게이트웨이인 MCe(Manufacturing Connect Edge) OS를 직접 설치하려 했을 때 직면한 문제입니다.
현장의 Dell 서버는 엔터프라이즈 환경의 안정성과 용량을 확보하기 위해 OS 영역(미러링된 디스크 2개)과 데이터 저장 영역(RAID 5로 묶인 디스크 4개), 총 2개의 논리적 드라이브(파티션)로 구성되어 있었습니다. 하지만 MCe의 공식 배포 이미지는 설치 시 단일 파티션(Single Volume) 구성만을 지원하는 제약이 있었습니다. 이로 인해 2개의 파티션으로 분리된 현장 서버의 스토리지 아키텍처를 MCe가 수용하지 못해 베어메탈 직접 설치가 불가능한 상황이었습니다.
가상화(Virtualization)를 통한 하드웨어 디커플링
하드웨어 파티션 제약을 소프트웨어적으로 풀기 위해, 베어메탈 직접 설치를 포기하고 가상화 레이어를 삽입하는 전략으로 선회했습니다.
- 물리 서버에 다중 파티션 및 하드웨어 드라이버 호환성이 뛰어난 Ubuntu OS를 우선 설치하여 하드웨어 제어권을 범용 OS에 넘겼습니다.
- 그 위에 VirtualBox 기반의 가상 환경을 구성하고, 가상 머신(VM)에 단일 가상 디스크를 할당하여 MCe 이미지를 배포했습니다.
이 우회 전략은 초기 세팅의 제약을 돌파했을 뿐만 아니라, 엣지에 문제가 생겼을 때 VM 스냅샷(Snapshot)을 통해 5분 만에 시스템을 롤백할 수 있는 뛰어난 운영 유연성(Resilience)까지 가져다주었습니다.
Challenge 2: 대용량 데이터 처리 한계와 Pub/Sub Payload 제한 극복
엣지 OOM(Out of Memory)과 클라우드의 물리적 한계
공장의 데이터는 센서 로그만 있는 것이 아닙니다. 수집 대상 중에는 파일 하나가 2GB를 초과하는 거대한 CSV 파일과 고해상도 품질 검사 이미지(JPG, BMP, PNG), 공정 영상(MPG, MP4)도 포함되어 있었습니다.
여기서 두 가지 물리적 한계에 부딪혔습니다. 첫째, 초기 표준 파이프라인 흐름대로 2GB 이상의 CSV 파일을 한 번에 메모리에 올려 직렬화하려다 MCe 엣지 단에서 OOM(Out of Memory)이 발생했습니다. 둘째, Google Cloud Pub/Sub의 메시지당 최대 허용 크기(Payload Limit)는 10MB로 제한되어 있어, 대용량 데이터를 직접 스트리밍으로 밀어 넣는 것 자체가 아키텍처상 불가능했습니다.
투트랙(Two-Track) 해결 전략: Chunking과 Claim-Check
이 문제를 해결하기 위해 엣지 레벨의 데이터 처리 방식과 클라우드 전송 아키텍처를 모두 수정하는 투트랙 전략을 취했습니다.
1. MCe 레벨의 청크(Chunk) 단위 분할 로딩
2GB 이상의 대용량 CSV 파일은 파일 전체를 한 번에 메모리에 로딩하는 기존 방식을 폐기했습니다. 대신 MCe 수집 흐름(Flow) 내부에서 파일을 여러 개의 작은 청크(Chunk)로 쪼개어 순차적(Incremental)으로 로딩·처리하는 방식으로 변경하여 엣지 단의 OOM 문제를 원천 차단했습니다.
2. Claim-Check 아키텍처 패턴 적용
클라우드 메시징 환경에서 대용량 페이로드를 처리하기 위한 표준 아키텍처인 Claim-Check 패턴을 적용하여 파이프라인 흐름을 두 갈래로 분리했습니다.
| 데이터 타입 | 크기 | 전송 경로 | 동작 방식 |
|---|---|---|---|
| Telemetry (센서) | 10MB 미만 | MCe → Pub/Sub | 표준 JSON 직렬화 후 실시간 스트리밍 전송 |
| Large Files (대용량 이미지, 영상) | 10MB 이상 | MCe → GCS | 원본 파일은 Cloud Storage(GCS) 버킷으로 직접 업로드 |
대용량 파일의 경우, Edge는 Pub/Sub에 실제 데이터 대신 “GCS 파일 경로(URI)와 메타데이터"만 포함된 수 KB의 가벼운 메시지(Claim-Check Token)만 전송합니다. 이후 Dataflow가 이 메시지를 구독하면, 해당 URI를 참조해 GCS에서 직접 데이터를 병렬로 읽어 처리함으로써 Pub/Sub의 네트워크 병목을 완벽히 해결했습니다.
Challenge 3: 데이터 정합성의 딜레마 (왜 숫자가 맞지 않는가?)
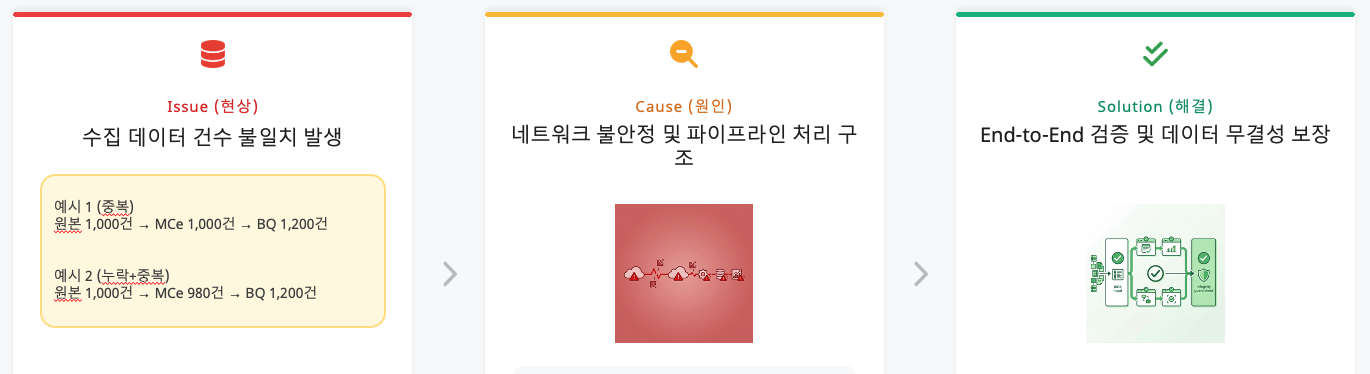
문제 상황: 데이터 엔지니어의 악몽
가장 끝까지 우리를 괴롭힌 이슈는 **‘수집 데이터 건수 불일치’**였습니다.
예시: 원본 CSV 파일의 라인 수는 1,000개인데, 엣지(InfluxDB)에는 980건만 저장되고(누락), 최종 종착지인 BigQuery에는 1,200건이 적재되는(중복) 현상.
심층 원인 분석: 중복과 누락의 이중주
디버깅 결과, 데이터가 늘어나고 줄어든 원인은 각각 다른 곳에 있었습니다.
1. 중복(Duplication)의 원인: BigQuery와 수동 개입
BigQuery는 데이터 수신 시 중복 여부를 체크하지 않고 무조건 적재(Append-only)하는 특성이 있습니다. 여기에 더해 파이프라인 검증을 위해 엔지니어들이 Pub/Sub에 데이터를 수동으로 주입하거나 재전송 테스트를 반복하면서 물리적인 데이터 양이 뻥튀기되었습니다.
2. 누락(Loss)의 원인: 원본 데이터의 중복과 MC의 필터링
더 심각한 문제는 ‘사라진 데이터’였습니다. 분석 결과, 현장에서 제공한 원본 CSV 파일 자체에 동일한 타임스탬프와 값을 가진 중복 데이터가 포함되어 있었습니다. **MC(Manufacturing Connect) 엣지는 이를 ‘동일 데이터’로 정확히 판단하여 중복 전송을 막기 위해 스스로 필터링(Drop)**했습니다. 결과적으로 시스템은 정상 작동했으나, 원본 파일의 물리적 라인 수와 적재된 데이터 수의 불일치를 초래하여 ‘누락’으로 오인하게 만들었습니다.
해결 방향: DLQ와 멱등성 보장
이러한 정합성 문제를 해결하기 위해 MDE 솔루션이 제공하는 Dead Letter Queue(DLQ) 기능과 멱등성(Idempotency) 보장 옵션을 활용하는 전략을 수립했습니다.
- 고유 ID 기반 멱등성: 데이터 생성 시점에 고유 ID(UUID)를 부여하여, 동일한 데이터가 재전송되더라도 중복 적재를 방지합니다.
- DLQ를 통한 오류 격리: 처리에 실패한 데이터를 별도 큐로 격리하여 메인 파이프라인의 정합성을 보호하고, 이후 분석 및 재처리할 수 있는 안전망을 확보합니다.
- BigQuery 중복 제거: 적재 후에도
MERGE또는ROW_NUMBER()기반의 Deduplication 쿼리를 통해 최종 데이터의 유일성을 보장합니다.
핵심 교훈
이번 PoC는 279TB라는 거대한 데이터를 클라우드로 옮기는 과정이었지만, 저에게는 책상 위에서 그린 아키텍처가 현장의 진흙탕 속에서 어떻게 무너지고 다시 세워지는지를 목격한 시간이었습니다. 이 프로젝트를 통해 배운 세 가지 교훈을 공유합니다.
현장의 하드웨어는 언제나 예상을 빗나간다 (Flexibility over Performance)
“표준 서버니까 당연히 설치되겠지"라는 안일한 생각은 현장의 구형 RAID 컨트롤러 앞에서 산산이 부서졌습니다. 엔지니어링의 세계에서 베어메탈의 성능 최적화는 매력적이지만, 변수가 통제되지 않는 엣지(Edge) 환경에서는 **‘유연성(Flexibility)‘이 곧 ‘생존(Survival)’**임을 배웠습니다. 가상화 레이어 한 장을 더하는 것은 오버헤드가 아니라, 예측 불가능한 하드웨어 이슈로부터 소프트웨어를 지키는 가장 확실한 보험이었습니다.
클라우드의 한계를 인정할 때 진짜 설계가 시작된다 (Design for Limits)
무한해 보이는 클라우드 리소스도 결국 물리적인 한계(Quota)를 가집니다. Pub/Sub의 10MB 제한이나 엣지 디바이스의 메모리 부족(OOM)을 마주했을 때, 단순히 용량을 늘려달라고 요청하는 것은 하수일 것입니다. 이 제약을 인정하고 Claim-Check나 Chunking 같은 아키텍처 패턴을 통해 우회로를 뚫었습니다. 진정한 엔지니어링은 제약 조건이 없는 환경이 아니라, 제약 조건 안에서 최적의 해법을 찾아낼 때 빛난다는 것을 다시 한번 확인했습니다.
정합성은 설계의 첫 단추다 (Consistency First)
대규모 데이터 파이프라인에서 정합성은 부가 기능이 아니라 핵심 설계 요소입니다. 원본 데이터의 중복이나 수동 테스트 과정에서의 부산물이 뒤섞이면 데이터의 신뢰성이 급격히 떨어집니다. **데이터 무결성 검증은 ‘사후 처리’가 아니라 ‘설계의 첫 단추’**입니다. 멱등성(Idempotency) 보장과 DLQ 설계를 파이프라인 코어에 내장하는 것이 279TB급 대규모 수집 시스템의 성공을 좌우하는 핵심 요소입니다.
이번 PoC를 통해 거친 이기종 데이터가 흐를 수 있는 ‘거대하고 튼튼한 파이프라인’을 건설하고, 멱등성·DLQ 기반의 데이터 정합성 안전망까지 설계했습니다. 이 경험을 바탕으로, AI 모델이 안심하고 마실 수 있는 **1급수(High-Quality Data)**를 안정적으로 공급하는 것이 제조 AI 파이프라인의 궁극적 목표입니다.
부록: Manufacturing Connect Edge (MCE) 설치 및 구성 가이드
이 가이드는 베어메탈 서버의 설치 난이도를 해결하기 위한 PINN PoC 프로젝트(한국) 전용 설정 방식임을 유의해 주시기 바랍니다. 실제 운영 환경에서의 설치 단계는 이와 다를 수 있습니다.
MC(Manufacturing Connect)와 MCE의 설치를 위해서는 물리적인 하드웨어, 클라우드 환경, 예산 등 준비해야 할 사항이 많아 실제 설치와 테스트가 까다로울 수 있으나, 아래 정리된 과정이 전체적인 흐름을 이해하는 데 도움이 되길 바랍니다.
디스크 구성은 다음과 같습니다.
/dev/sda: 300GB. RAID 1(Mirroring) 구성. Ubuntu OS 설치 영역./dev/sdb: 32TB. RAID 5 구성. InfluxDB 데이터 저장 영역.
Ubuntu 리눅스 설치 및 네트워크 설정
가장 먼저 기본 운영체제인 Ubuntu를 설치하고 네트워크를 구성합니다.
- OS 설치: 부팅 가능한 USB를 통해 “Try or Install Ubuntu"를 선택하여 설치를 진행합니다.
- 네트워크 설정: ‘Advanced Network Connection’에서 IP, 게이트웨이, 서브넷 마스크, DNS를 설정합니다.
- 방화벽 활성화: 보안을 위해 UFW 방화벽을 켭니다.
# 방화벽 활성화
sudo ufw enable
시스템 업데이트 및 데이터 디스크 포맷 (32TB)
시스템을 최신 상태로 유지하고 대용량 하드 드라이브를 파티셔닝합니다.
# 시스템 업데이트
sudo apt update
# 디스크 확인 및 기존 파티션 삭제
sudo lsblk
sudo wipefs -a /dev/sdb
sudo sgdisk --zap-all /dev/sdb
# GPT 파티션 생성 (Parted 사용)
sudo parted /dev/sdb
# (parted 프롬프트 진입 후)
mklabel gpt
mkpart primary ext4 0% 100%
print
quit
# 파일 시스템 포맷 (EXT4 또는 필요시 XFS)
sudo mkfs.ext4 /dev/sdb1
# 또는 sudo mkfs.xfs /dev/sdb1
# 마운트 및 자동 마운트 설정
sudo mkdir -p /mnt/data
sudo mount /dev/sdb1 /mnt/data
# UUID 확인 후 /etc/fstab에 추가하여 재부팅 시 자동 마운트
sudo blkid /dev/sdb1
# 예: UUID=abcd-1234 /mnt/data ext4 defaults 0 2
VirtualBox 설치 및 KVM 비활성화
MCE는 가상 환경에서 실행되므로 VirtualBox를 설치합니다. 이때 충돌 방지를 위해 KVM 모듈을 반드시 비활성화해야 합니다.
# VirtualBox 설치
sudo apt install virtualbox
# 현재 세션에서 KVM 모듈 제거 (Intel CPU 기준)
sudo modprobe -r kvm_intel
# KVM 영구 블랙리스트 추가
sudo nano /etc/modprobe.d/kvm.conf
# 파일 내부에 'blacklist kvm_intel' 입력 후 저장
# 커널 이미지 업데이트 및 재부팅
sudo update-initramfs -u -k all
sudo reboot
MCE(Manufacturing Connect Edge) 설치 및 자동 시작 설정
ISO 이미지를 통해 MCE를 설치한 후, 서버 재부팅 시 VM이 자동으로 시작되도록 설정합니다.
- 설치 가이드: Litmus Edge VirtualBox 설치 문서를 참조하세요.
- 자동 시작 설정: ‘Startup Applications’ 유틸리티에 아래 명령어를 추가합니다.
# VM 자동 실행 명령어 (Headless 모드 추천)
VBoxManage startvm "사용자_VM_이름" --type headless
호스트 설정 및 MC 활성화
관리 콘솔(MC) 접속을 위한 도메인 및 IP 설정을 진행합니다.
/etc/hosts파일에mz.co.kr을 추가합니다.mz.co.kr로 접속하여 비밀번호를 변경합니다.- Admin UI > Settings > Entry Points에서 도메인을 MC의 프라이빗 IP로 변경합니다 (반영까지 약 8분 소요).
- JSON SA 키를 업로드하고 MCE를 활성화합니다.
최종 점검 사항
모든 설정이 완료되면 서버를 재부팅하여 다음 사항을 확인하십시오.
- MCE(Manufacturing Connect Edge)가 자동으로 부팅되는가?
