
250+ 산업 프로토콜 지원 · Edge-to-Cloud 파이프라인 · 물리적 수준의 프로젝트 격리
보안과 비용의 Trade-off를 고려한 Manufacturing Data Engine 실전 구축기
Cloud Tech Unit · GCP Delivery SA 3 윤성재 | 2026-02-23
사업 배경 — PINN 모델 기반 융합데이터 플랫폼
제조 산업의 디지털 전환(DX)에 있어 가장 큰 허들은 현장의 IT와 OT 데이터를 클라우드로 안전하고 끊김 없이 옮기는 ‘라스트 마일(Last Mile)‘에 있습니다.
이 글은 대한민국 정부 주도로 진행된 ‘2025년 PINN(Physics-Informed Neural Networks) 모델 제조 융합데이터 수집·실증 사업’의 클라우드 인프라 파트너로서, 8개 제조 기업의 이기종 데이터를 Google Cloud Manufacturing Data Engine(MDE) 기반으로 통합 구축한 사례를 다룹니다.
초기 사업수행계획서상의 수집 목표는 185TB였으나, 250개 이상의 산업 프로토콜을 수용하는 고성능 파이프라인을 구축하여 목표 대비 150%를 초과한 총 279TB의 제조 데이터(시계열 센서, 이미지, 영상 등)를 성공적으로 수집했습니다. 이 글에서는 그 거대한 데이터 댐을 구축하기 위해 치열하게 고민했던 아키텍처 의사결정(ADR)을 공유합니다.
문제 정의 — OT-IT 융합의 3가지 딜레마
성공적인 PINN 모델 학습을 위해서는 고품질의 원시 데이터(Raw Data)가 필수적입니다. 하지만 프로젝트의 핵심인 ‘IT-OT 융합’ 을 실현하려면 먼저 두 영역의 데이터가 갖는 성격과 차이를 이해해야 했습니다.
- IT(정보기술) 데이터: ERP, MES 등 업무를 지원하는 경영 시스템에서 생성되는 데이터
- OT(운영기술) 데이터: PLC, SCADA 등 물리적 설비를 제어하고 생산을 담당하는 현장 기술에서 생성되는 데이터
이 두 영역을 하나로 모으는 과정에서 다음과 같은 현실적인 장벽에 부딪혔습니다.
파편화된 설비 환경과 프로토콜 (Heterogeneous Environment)
8개 공장은 각기 다른 장비를 사용하고 있었습니다. IT 영역에서는 ERP, MES 등의 시스템마다 사용 중인 데이터베이스가 서로 달랐고, OT 영역 역시 공장마다 도입한 설비 제조사가 상이했습니다. 설상가상으로 수집 대상 데이터 포맷 또한 CSV, JSON, Parquet 등의 정형 데이터부터 이미지(JPG, PNG, BMP 등), 영상(MPG, MP4 등)과 같은 비정형 데이터까지 혼재되어 있어, 이를 아우르는 표준화된 수집 체계를 마련하기가 매우 어려웠습니다.
네트워크 대역폭 한계와 데이터 유실 위험 (Network Reliability)
제조 현장의 네트워크 환경은 대용량 데이터를 클라우드로 전송하기에 열악했습니다. 외부 인터넷 연동 구간은 회선 이중화가 부재했고, 기존 내부 업무망과 회선을 공유하여 사용함에 따라 고질적인 대역폭 부족 문제가 발생했습니다. 네트워크 지연이나 단절이 발생하는 순간에도 데이터는 유실 없이 엣지 단에서 안전하게 버퍼링되어야 하며, 망 복구 시 누락 없이 순서대로 클라우드에 전송될 수 있는 강건한 아키텍처가 필요했습니다.
엄격한 기업 간 데이터 격리 (Strict Multi-Tenancy)
참여하는 8개 제조 기업은 잠재적 경쟁사일 수 있습니다. 클라우드라는 ‘공유 자원’을 사용하면서도, 기업 간 데이터 혼입 우려를 완전히 불식시키는 물리적 수준의 논리적 격리(Isolation)가 프로젝트 성패의 핵심이었습니다.
전체 아키텍처 — Edge-to-Cloud Pipeline
위 문제를 해결하기 위해 Google Cloud의 특화 솔루션인 MDE(Manufacturing Data Engine)와 MC(Manufacturing Connect)를 코어로 채택했습니다. 전체 아키텍처는 “현장 설비에 영향을 주지 않는다"는 대원칙 하에 4개의 Layer로 설계되었습니다.
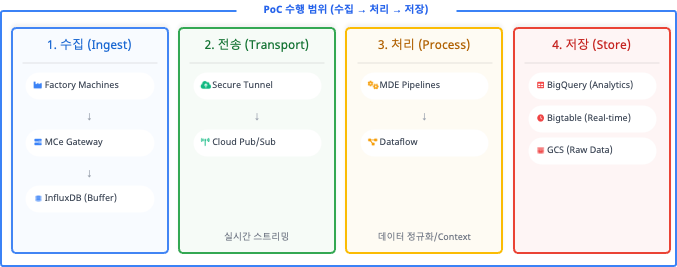
| Layer | 컴포넌트 | 주요 역할 |
|---|---|---|
| Edge | MCe (Manufacturing Connect Edge) | 현장 네트워크 내 위치. 250개 이상의 프로토콜 지원. 네트워크 단절 시 InfluxDB를 활용한 엣지 로컬 버퍼링 수행 |
| Transport | Cloud Pub/Sub | 초당 수백만 건의 이벤트를 처리하는 대용량 비동기 스트리밍. 트래픽 스파이크 발생 시 시스템 다운을 막는 완충 지대 역할 |
| Processing | Cloud Dataflow | 실시간 데이터 정규화(Normalization). 센서 값에 설비명·라인 위치 등 메타데이터를 결합(Contextualization)하여 비즈니스 가치 부여 |
| Storage | BigQuery / Bigtable / GCS | 람다 아키텍처(Lambda Architecture) 차용. 대용량 분석용 BQ, 실시간 조회용 BT, 대용량 파일용 Cloud Storage로 분산 적재 |
핵심 의사결정 — 보안과 비용의 Trade-off
클라우드 아키텍트로서 가장 고민했던 부분은 ‘멀티 테넌시(Multi-tenancy) 환경을 어떻게 설계할 것인가’였습니다. 수집 대상이 8개의 서로 다른(그리고 잠재적 경쟁 관계일 수 있는) 기업들이었기 때문에 데이터 격리 수준에 대한 아키텍처 결정이 필요했습니다.
대안 A: 단일 프로젝트 내 데이터셋 기반 격리 (Dataset-level Isolation)
하나의 통합된 GCP 프로젝트 내에 모든 공장의 데이터 파이프라인(Pub/Sub, Dataflow 등)을 중앙 집중화하고, 데이터가 적재되는 최종 저장소(BigQuery) 단계에서만 ‘공장별 데이터셋(Dataset)‘을 생성하여 논리적으로 격리하는 방식입니다.
- 장점 (Pros): 인프라 자원을 8개 공장이 공유하므로 컴퓨팅 리소스의 낭비를 막고 비용 최적화(Cost Efficiency)에 매우 유리합니다. 또한 단일 포인트에서 파이프라인 모니터링과 배포를 수행할 수 있어 운영 관리 효율성이 높습니다.
- 단점 (Cons): 여러 기업의 데이터가 동일한 메모리(Dataflow 워커)와 큐(Pub/Sub)를 거쳐가기 때문에, IAM 권한 설정이나 파이프라인 코드상의 미세한 실수(Misconfiguration)로 인해 타 기업의 데이터가 혼입되거나 노출될 잠재적 보안 리스크가 존재합니다.
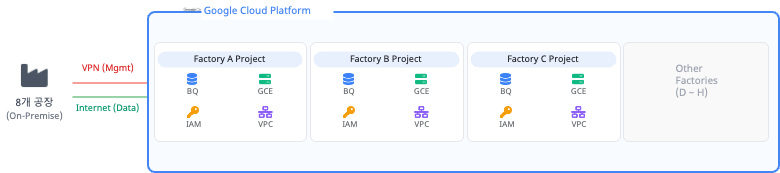
대안 B: 공장별 독립 프로젝트 기반 격리 (Project-level Isolation)
8개 공장 각각에 완전히 독립된 GCP 프로젝트를 할당합니다. 공장마다 고유한 VPC 네트워크, Pub/Sub, Dataflow 워커, BigQuery 인스턴스를 별도로 구축하여 수집부터 저장까지의 모든 데이터 흐름을 물리적으로 차단하는 방식입니다.
- 장점 (Pros): 프로젝트 단위로 경계가 완벽히 분리되므로 데이터 혼용 가능성을 원천 차단할 수 있어 보안성(Security)과 데이터 독립성이 극대화됩니다. 프로젝트 단위의 IAM 권한 부여로 접근 제어가 명확하며, 비용 정산(Billing) 역시 프로젝트별로 깔끔하게 분리되어 투명성을 확보할 수 있습니다.
- 단점 (Cons): 동일한 인프라(VPC, 로깅, 파이프라인 등)를 8벌이나 띄워야 하므로 유지 비용(TCO)이 대폭 상승합니다. 데이터 유입량이 적은 공장에도 고정적인 Dataflow 워커가 할당되어 유휴 자원이 발생하며, 8개의 환경을 개별적으로 패치하고 모니터링해야 하므로 운영 관리의 복잡도가 매우 높아집니다.
Architect’s Note: 초기 설계 단계에서는 확장성과 비용 효율성(대안 A)의 유혹이 컸습니다. 하지만 정부 실증 사업의 특성상 참여 기업들의 보안 우려(경쟁사 간 데이터 유출)를 원천 차단해야 하는 것이 프로젝트 성패의 핵심이었습니다. 결과적으로 비용 효율성과 운영 편의성을 크게 희생하더라도, 물리적 수준의 격리를 제공하는 Project-level Isolation(대안 B)을 최종 채택했습니다.
네트워크 보안 — 전송망 이원화
제조(OT) 망의 폐쇄성을 존중하기 위해 네트워크 트래픽을 이원화했습니다.
- Management Traffic: MC 중앙 서버에서 엣지(MCe)로 배포되는 펌웨어 업데이트 및 구성(Configuration) 관리는 오직 VPN(Private) 터널을 통해서만 이루어지도록 통제했습니다.
- Data Traffic: 테라바이트급 센서 데이터는 VPN 대역폭으로 감당할 수 없으므로, TLS로 암호화된 Public 인터넷 회선을 통해 GCP Pub/Sub 엔드포인트로 직접 전송하도록 분리 설계했습니다.
핵심 교훈
완벽한 격리의 대가와 비용 최적화 필요성
철저한 프로젝트 격리는 보안 측면에서 훌륭했지만, 각 공장마다 Dataflow 워커와 모니터링 환경이 중복 생성되어 유휴 자원(Idle Resource)이 다수 발생했습니다. 향후 본 사업 확장 시에는 Shared VPC를 기반으로 인프라는 공유하되 데이터만 논리적으로 완벽히 격리하는 하이브리드 접근법을 도입해야 합니다.
데이터 거버넌스 표준화의 중요성
동일한 ‘온도’ 데이터라도 A공장은 temp_1, B공장은 temperature_val 등 명명 규칙이 달랐습니다. 통합 PINN 모델 학습을 위해서는 데이터 수집 전 단계에서 스키마 표준화 및 전사 메타데이터 사전에 대한 룰셋을 확립하는 것이 핵심입니다.
AI와 분석을 위한 다음 단계
이번 PoC는 융합데이터가 안전하게 흐를 수 있는 강력한 ‘고속도로’를 개통한 셈입니다. 향후 진행될 본 사업에서는 수집된 데이터를 바탕으로 Looker 대시보드를 통한 시각화와 Vertex AI 기반의 예지보전 PINN 모델 개발이라는 진정한 비즈니스 가치 창출 단계로 나아갈 것입니다.
