(주)경농 파밍노트 고도화 프로젝트 — 농약 제품 사진 한 장으로 제품 정보를 자동 검색하는 AI 시스템의 설계와 구현 과정을 공유합니다.
프로젝트 배경
경농은 이전 단계에서 AWS, 메가존클라우드와 함께 생성형 AI 기반 농업 전문 챗봇을 구축한 바 있습니다. Amazon Bedrock Claude Sonnet 3.5와 OpenSearch를 활용한 RAG 아키텍처로, 농업인이 자연어로 질문하면 작물보호제 정보를 자동으로 응답하는 서비스였습니다.
이 챗봇을 운영하던 중, 경농으로부터 현장의 의미 있는 피드백과 함께 새로운 제안을 받았습니다. 고령의 농업인이 많은 현장 특성상, 스마트폰으로 길고 생소한 농약 제품명을 직접 타이핑하는 것을 매우 번거로워하신다는 점이었습니다.
“현장에서 스마트폰으로 제품을 촬영하기만 해도 정보를 바로 찾아줄 수 없을까?” — 고객사의 이러한 고민을 바탕으로, 텍스트 입력을 넘어선 시각적 검색 시스템을 구축하는 고도화 프로젝트가 시작되었습니다.
문제는 단순하지 않았습니다. 현장에서 찍은 사진은 흐릿하거나 회전되어 있고, 한글·숫자·특수문자가 뒤섞인 라벨에서 Vision LLM이 텍스트를 완벽하게 읽어내기란 어렵습니다. 약 4,000종의 유사한 제품명 사이에서 “바테스다"가 “바테스타"의 오인식인지 아예 다른 제품인지 구분해야 합니다. 그래서 OCR이 틀려도 제품을 찾는 시스템을 만들어야 했습니다.
시스템 아키텍처

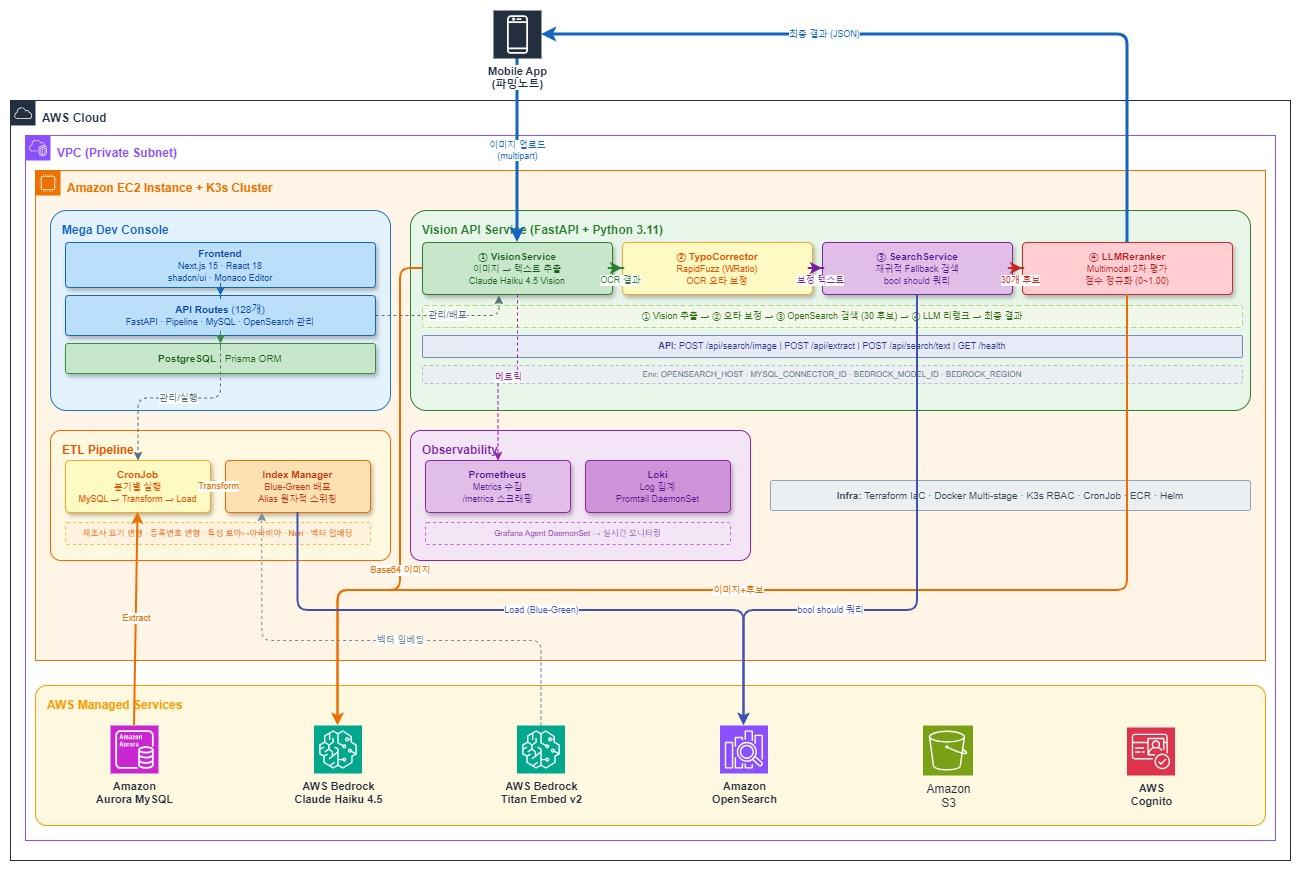
시스템 아키텍처 — AWS 관리형 서비스 연동
사용자가 농약 제품 이미지를 업로드하면, 시스템은 3단계를 순차적으로 수행합니다. 각 단계는 이전 단계의 불완전함을 보완하도록 설계되어 있습니다.
Stage 1 — Vision LLM이 라벨을 읽고 (제품명, 등록번호, 제조사 추출)
TypoCorrector가 OCR 오타를 보정
Stage 2 — OpenSearch가 계층적 Fallback으로 후보군 검색
(정확 일치부터 부분 매칭까지 한 번의 쿼리로)
Stage 3 — LLM Reranker가 원본 이미지를 다시 보고 최종 순위 결정
이 글의 나머지 부분은 각 단계를 상세히 다룹니다.
OCR이 틀려도 제품을 찾는 법
Vision LLM: 라벨에서 정보 추출
이미지에서 텍스트를 추출하는 것은 일반적인 OCR과 다릅니다. 단순히 텍스트를 읽는 것이 아니라, “농약 제품 라벨"이라는 도메인 지식을 바탕으로 구조화된 정보를 추출해야 합니다.
압축 JSON 전략
Vision LLM의 응답 속도를 최적화하기 위해, 출력 토큰을 최소화하는 압축 JSON 포맷을 설계했습니다:
LLM이 반환하는 압축 형식:
{"s":"C","n":"바테스타","g":"46-제초-546","m":"팜한농","i":"메톨라클로르 입제","c":{"n":0.95,"g":0.9,"m":0.9,"i":0.85}}
서버에서 표준 형식으로 변환:
{
"status": "CLEAR",
"product_name": "바테스타",
"registration_number": "46-제초-546",
"manufacturer": "팜한농",
"ingredient_name": "메톨라클로르 입제",
"confidence": {
"product_name": 0.95,
"registration_number": 0.9,
"manufacturer": 0.9,
"ingredient_name": 0.85
}
}
max_tokens: 500, temperature: 0.0으로 설정하여 결정론적이고 간결한 출력을 유도합니다. 모든 필드에 0.0~1.0 신뢰도를 함께 반환받아 후속 처리를 동적으로 조절합니다. 신뢰도가 중간 수준인 필드에는 오타 보정을 시도하고, 보정 후에도 신뢰도가 낮은 필드는 검색 쿼리에서 제외하여 오검색을 방지합니다.
프롬프트를 통한 디자인 텍스트 인식 극복
농약 제품명은 주목도를 높이기 위해 화려한 캘리그라피나 독특한 타이포그래피로 디자인된 경우가 많습니다. 초기 테스트에서는 Vision LLM이 이러한 디자인된 글자를 텍스트가 아닌 그림으로 오인하는 경우가 발생했습니다. 우리는 프롬프트에 **“제품명은 라벨에서 가장 크고 눈에 띄는 텍스트(largest text)이다”**라는 시각적 컨텍스트를 명시적으로 제공했습니다. 이 간단한 지침만으로 모델은 시각적 레이아웃 내에서의 중요도를 파악하게 되었고, 복잡하게 디자인된 제품명도 텍스트로 정확히 추출하기 시작했습니다.
이미지 상태 분류
텍스트를 추출하기 전에, 이미지 자체의 상태를 먼저 진단합니다. CLEAR(정상), ROTATED(회전됨), MULTIPLE(여러 제품), NOT_FOUND(제품 미감지)의 4가지 상태를 분류하여, CLEAR가 아닌 경우에는 사용자에게 재촬영을 안내합니다. 이때 동일 제품 여러 개(예: 모벤토 3병)는 CLEAR로, 서로 다른 제품이 함께 있을 때만 MULTIPLE로 처리합니다.
등록번호 추출의 난이도
농약 등록번호는 숫자-용도-숫자 형식(예: 46-제초-546)을 따르는데, 라벨 상에서 위치가 일정하지 않고 “H5”, “H8” 같은 위험물 코드와 혼동되기 쉽습니다. 프롬프트에 구분 기준을 명시했습니다:
* Format: number-[살충|제초|살균]-number (e.g., "46-제초-546")
* If you see "H5", "H8" etc. those are hazard codes, NOT registration numbers
* Registration number middle part must be 살충, 제초, or 살균
TypoCorrector: OCR 오타 보정
Vision LLM이 아무리 뛰어나도, 흐릿하거나 부분적으로 가려진 라벨에서는 오인식이 발생합니다. “바테스타"를 “바테스다"로, “팜한농"을 “팜한롱"으로 잘못 읽을 수 있습니다. 이 오타를 그대로 검색 쿼리에 넣으면 검색이 실패합니다.
서버 시작 시 OpenSearch에서 전체 제품명(약 4,000개)과 제조사(약 200개)를 메모리에 캐싱해두고, RapidFuzz 라이브러리의 WRatio 스코어러를 사용합니다. WRatio는 여러 유사도 측정 방식을 조합하여 최적의 점수를 반환하므로, “바테스다"처럼 1~2글자가 틀리거나 제품명이 일부만 읽힌 경우에도 원래 제품명을 매칭하는 데 효과적입니다:
# 제품명: threshold 75 (관대하게 — 오타가 많을 수 있으므로)
result = process.extractOne(
input_name, # OCR 결과: "바테스다"
self.product_names_cache, # 실제 제품 목록
scorer=fuzz.WRatio,
score_cutoff=75
)
# → "바테스타" (score: 95.5) 매칭
# 제조사: threshold 80 (엄격하게 — 짧은 이름은 오매칭 위험이 높으므로)
제품명은 threshold 75로 관대하게, 제조사는 80으로 엄격하게 설정했습니다. 제조사 이름이 짧아서 낮은 임계값에서는 엉뚱한 이름에 매칭되는 경우가 잦았기 때문입니다. 오타가 보정되면 해당 필드의 신뢰도를 0.2 상향 조정하여, 보정된 결과가 검색 쿼리에 안정적으로 반영되도록 합니다.
계층적 Fallback 검색
TypoCorrector를 거쳐도 OCR 결과가 완벽하지 않을 수 있습니다. 제품명의 앞부분만 읽혔거나, 일부 글자가 여전히 틀릴 수 있습니다. 단순한 Exact Match만으로는 이런 경우를 커버할 수 없어서, 한 번의 쿼리 안에 다양한 수준의 매칭을 계층적으로 포함하는 전략을 구현했습니다.
제품명 “바테스타"를 예로 들면, 시스템이 자동으로 생성하는 검색 패턴은 이렇습니다:
"바테스타" → exact match (boost: 100) ← 정확히 일치하면 최우선
"바테스*" → prefix match (boost: 45) ← "바테스타", "바테스톤" 등
"*테스타" → suffix match (boost: 45) ← "바테스타", "마스테스타" 등
"테스*" → prefix match (boost: 40) ← 더 짧은 prefix
"*스타" → suffix match (boost: 40) ← 더 짧은 suffix
여기에 등록번호(boost 80), 제조사(boost 30), 품목명(boost 20) 등 다른 필드의 매칭도 함께 조합됩니다. 이 패턴들이 하나의 bool should 쿼리로 묶여서 OpenSearch에 단일 API 호출로 전송됩니다:
search_query = {
"bool": {
"should": [
{"term": {"trdmk_nm.keyword": {"value": "바테스타", "boost": 100}}},
{"wildcard": {"trdmk_nm.keyword": {"value": "바테스*", "boost": 45}}},
{"wildcard": {"trdmk_nm.keyword": {"value": "*테스타", "boost": 45}}},
{"wildcard": {"trdmk_nm.keyword": {"value": "테스*", "boost": 40}}},
{"wildcard": {"trdmk_nm.keyword": {"value": "*스타", "boost": 40}}},
{"term": {"reg_no.keyword": {"value": "46-제초-546", "boost": 80}}},
{"match": {"mfr_nm": {"query": "팜한농", "boost": 30}}}
],
"minimum_should_match": 1
}
}
boost 값의 설계 근거는 단순합니다. 제품명 정확 일치(100)가 가장 확실한 식별자이고, 등록번호(80)는 고유 식별 번호라 일치하면 거의 확실합니다. wildcard는 base 50에서 줄어든 글자 수 × 5를 감산하여(50 - (len(product_name) - len(prefix)) * 5), 정확도가 떨어질수록 boost가 점진적으로 낮아지도록 설계했습니다. 제조사(30)와 품목명(20)은 보조 정보로만 활용합니다.
여기서 Leading Wildcard(*스타) 검색은 인덱스 전체를 스캔하므로 성능 부담이 크지만, 약 4,000종 규모의 농약 제품군에서는 체감할 수 있는 응답 지연이 발생하지 않았습니다. 따라서 복잡한 인덱스 튜닝보다는 검색 누락을 방지하는 재현율(Recall) 확보를 최우선으로 고려한 트레이드오프(Trade-off) 전략을 선택했습니다. 이렇게 30개 후보를 뽑아서 다음 단계로 넘깁니다.
LLM Reranker: 최적화된 최종 판단
OpenSearch가 뽑은 30개 후보는 키워드 매칭 결과이므로, 의미적·시각적 유사성까지 판단하기는 어렵습니다. 여기서 LLM Reranker가 최종 순위를 매깁니다.
속도와 비용을 위한 전략
모든 요청에 대해 LLM이 이미지를 다시 분석하는 것은 비용과 레이턴시(Latency) 면에서 비효율적입니다. 우리는 이를 해결하기 위해 두 가지 최적화 전략을 적용했습니다:
- Candidate Filtering (후보군 압축): OpenSearch 검색 결과에서 제품명이 정확히 일치(Exact Match)하는 후보가 발견되면, 30개 전체가 아닌 해당 후보들(보통 1~2개)만 추려내어 Reranker에 전달합니다. 이를 통해 LLM이 처리해야 할 프롬프트 길이를 대폭 줄여 응답 속도와 비용을 최적화했습니다.
- Precision Reranking (정밀 검증): 압축된 후보군에 대해서는 원본 이미지와 함께 멀티모달 리랭킹을 수행합니다. 이는 동일한 제품명이라도 제형(입제/수화제)이나 용량이 다른 미세한 차이를 최종적으로 구분하기 위함입니다. 불필요한 연산은 줄이되, 정확도는 타협하지 않는 전략입니다.
prompt = f"""추출된 정보와 가장 일치하는 후보를 찾아 점수를 매겨주세요.
추출 정보:
제품명: 돌격대 / 제조사: 경농(주) / 등록번호: 52-제초-178
후보 제품들:
0. 돌격대 (제조사: 경농(주), 등록번호: 52-제초-178, 성분: 벤타존 입제)
1. 돌격대 (제조사: 경농(주), 등록번호: 52-제초-179, 성분: 벤타존 수화제)
2. 공격대 (제조사: 팜한농, 등록번호: 46-제초-333, 성분: 글리포세이트)
...
각 후보의 관련성 점수를 배열로만 반환: [1.00, 0.85, 0.12, ...]
"""
이 3단계 파이프라인의 핵심은 각 단계가 이전 단계의 약점을 보완한다는 점입니다. Vision LLM이 틀려도 TypoCorrector가 잡고, TypoCorrector가 못 잡아도 Fallback 검색이 후보를 확보하며, 후보가 여러 개여도 Reranker가 원본 이미지를 다시 보고 최종 판단합니다.
데이터 파이프라인
검색 품질은 인덱스 데이터의 품질에 직결됩니다. ETL 파이프라인은 원본 MySQL 데이터를 검색에 최적화된 형태로 변환합니다.
한국 농약 시장의 특성상 동일한 정보가 다양하게 표기됩니다. 등록번호 “46-제초-546"은 “제46-제초-546"으로도 쓰이고, “(주)팜한농"은 “팜한농”, “팜한농(주)”, “주식회사 팜한농” 등으로 나타납니다. “살균"과 “살균제”, 로마 숫자 “Ⅲ급"과 아라비아 “3급"도 혼용됩니다. ETL에서 이런 변형들을 미리 생성해두면, 어떤 표기로 검색하든 매칭이 됩니다.
인덱스에는 한국어 Nori Tokenizer를 적용하여 형태소 단위로 토큰화하고, 동의어 확장(“살균” → “살균”, “살균제”)도 수행합니다.
Blue-Green 배포
농약 제품 데이터는 주기적으로 업데이트됩니다. 검색 서비스를 중단하지 않고 인덱스를 갱신하기 위해, 새 인덱스를 만들고 데이터를 적재한 뒤 Alias를 원자적으로 스위칭하는 Blue-Green 전략을 사용합니다:
def switch_alias(self, new_index: str) -> None:
actions = []
current_index = self.get_current_index()
if current_index:
actions.append({"remove": {"index": current_index, "alias": self.alias_name}})
actions.append({"add": {"index": new_index, "alias": self.alias_name}})
# 원자적 실행 → 스위칭 순간에도 요청 유실 없음
self.client.indices.update_aliases(body={"actions": actions})
이전 인덱스 2개를 보관하여 문제 발생 시 즉시 롤백할 수 있습니다.
AI 기반 통합 운영 플랫폼 구축
3개의 서비스(Vision API, ETL Pipeline, Console)를 효율적으로 운영하기 위해 Next.js 15 기반의 통합 관리 콘솔(Mega Dev Console)을 자체 개발했습니다. 단순히 API 호출을 돕는 도구를 넘어, AI를 활용한 운영 자동화 기능들을 함께 구현했습니다.

실제 촬영한 농약 제품(사파이어) — 이 이미지를 API에 업로드하여 제품 정보를 자동 추출
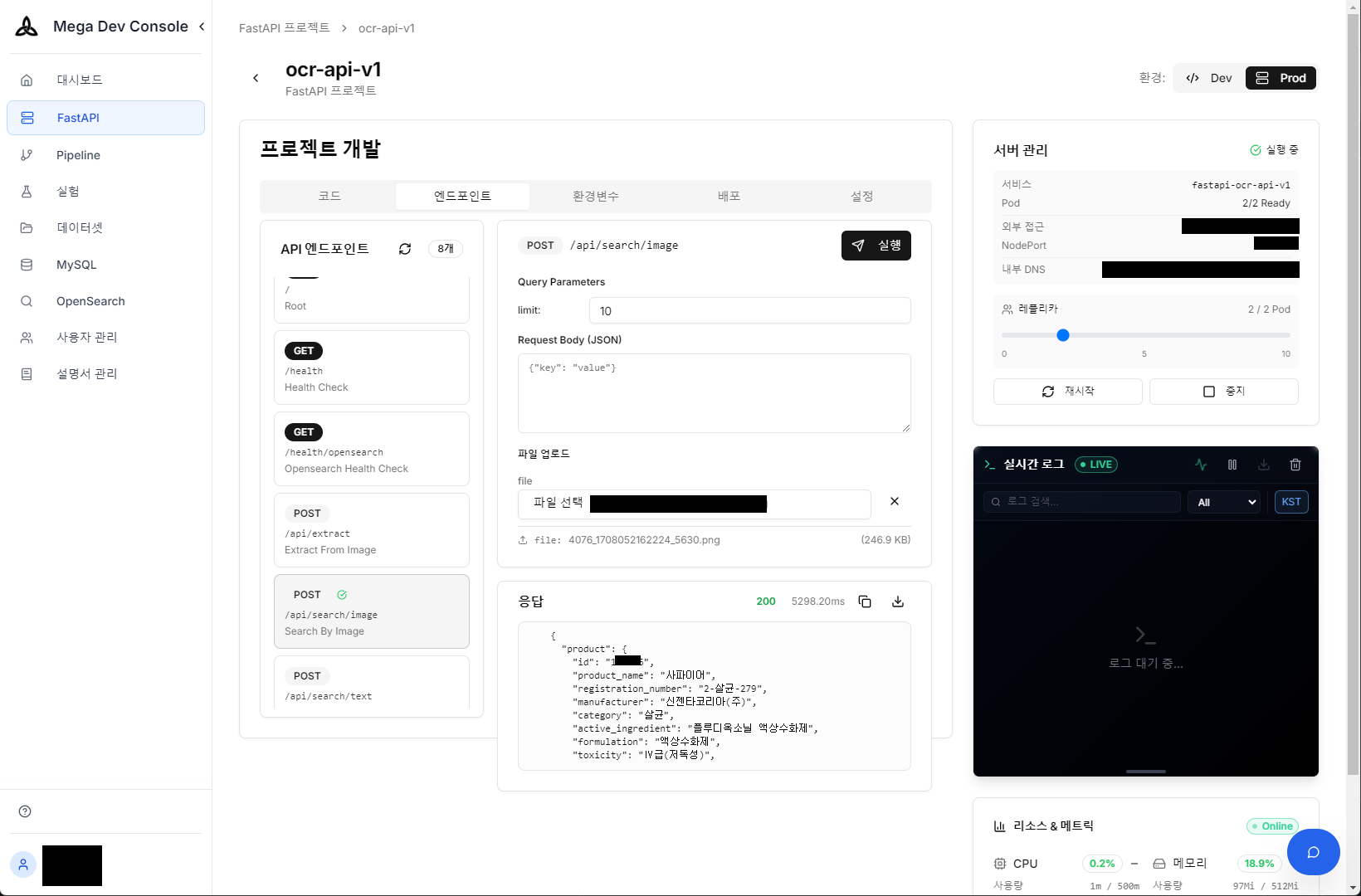
Vision API 실시간 테스트 — 이미지 업로드 후 추출된 제품 정보와 신뢰도(JSON)를 즉시 확인
특히 AI를 활용한 생산성 도구들이 개발팀의 운영 부담을 크게 덜어주었습니다.
1. 대화형 쿼리 생성 (Text-to-SQL/DSL)
복잡한 OpenSearch DSL이나 MySQL SQL을 직접 짤 필요가 없습니다. “사파이어 갯수가 총 몇개이며 어떻게 있어?“라고 자연어로 질문하면, AI가 DB 스키마를 이해하고 최적화된 쿼리(SQL 또는 DSL)를 생성하여 실행 결과까지 즉시 보여줍니다.
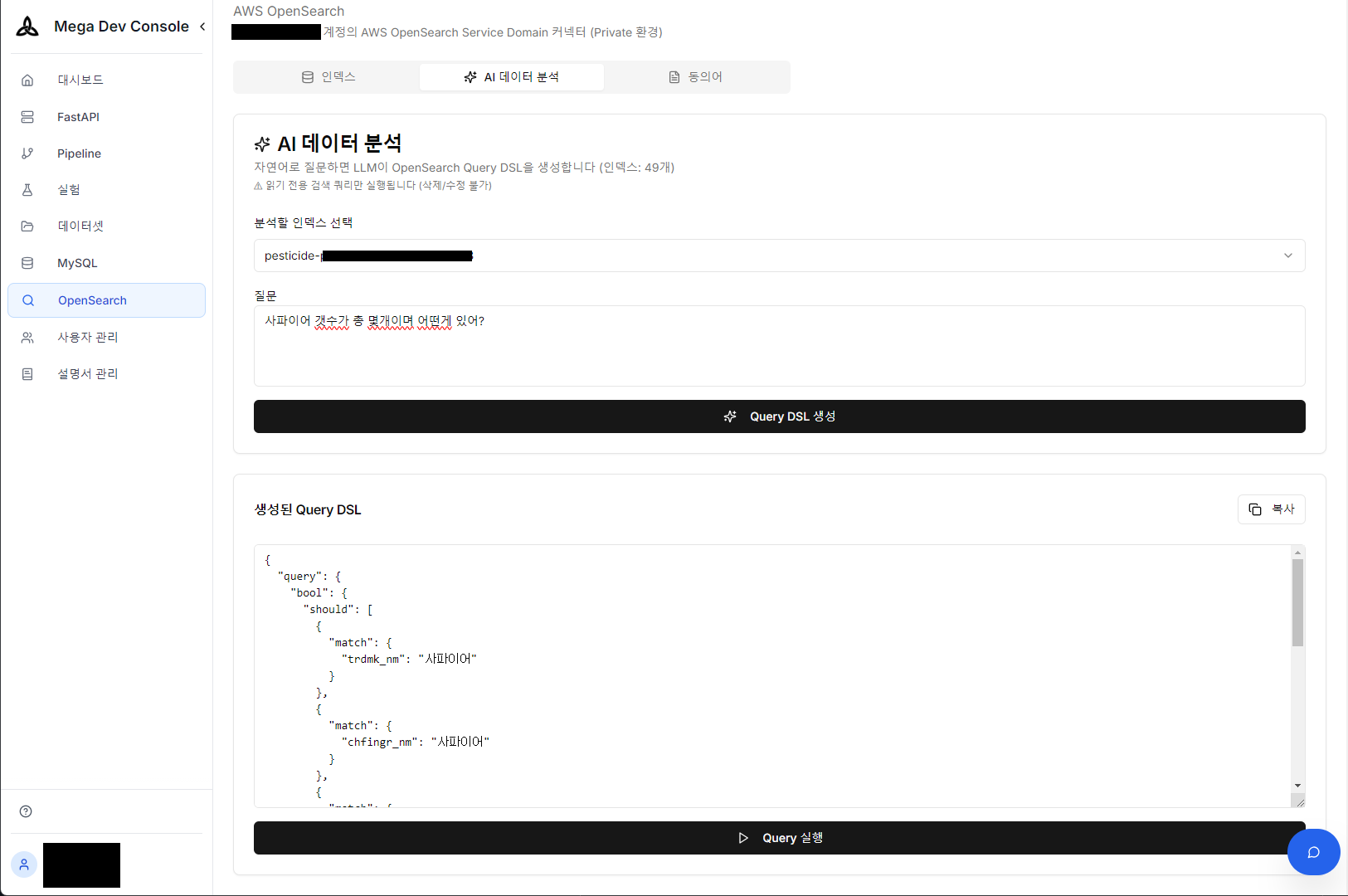
자연어 질문 → OpenSearch Query DSL 자동 생성
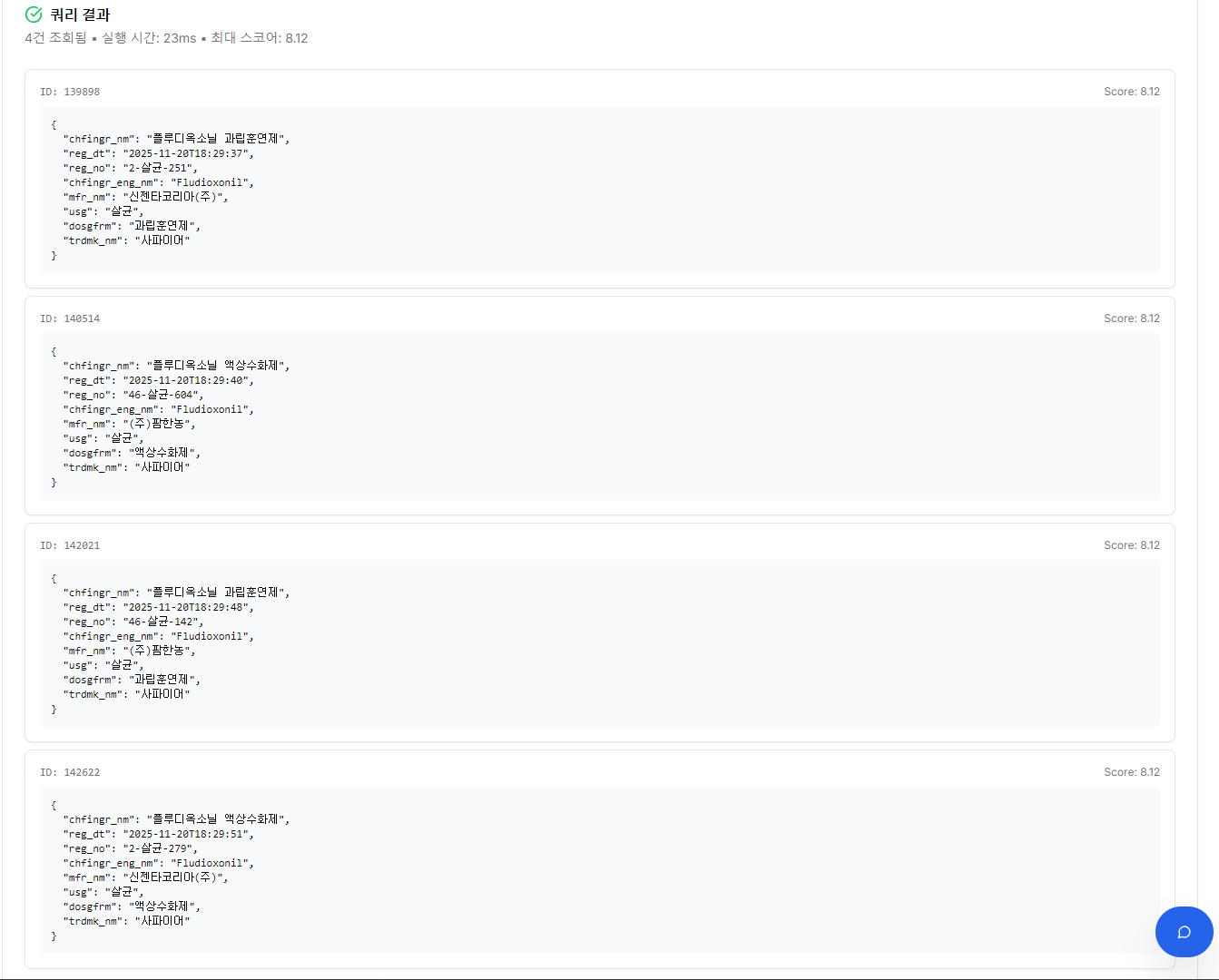
생성된 DSL 실행 결과 — “사파이어” 제품 4건 조회
2. AI 메타데이터 자동 생성
수천 장의 제품 이미지에 일일이 메타데이터를 입력하는 것은 상당한 시간과 비용이 소모되는 고된 작업입니다. AI 프롬프트 빌더를 통해 이미지에서 제품명, 용도, 이미지 품질 등의 메타데이터 초안을 자동으로 추출하고 DB에 태깅하여, 학습/검증용 데이터셋 구축 과정을 획기적으로 단축했습니다.
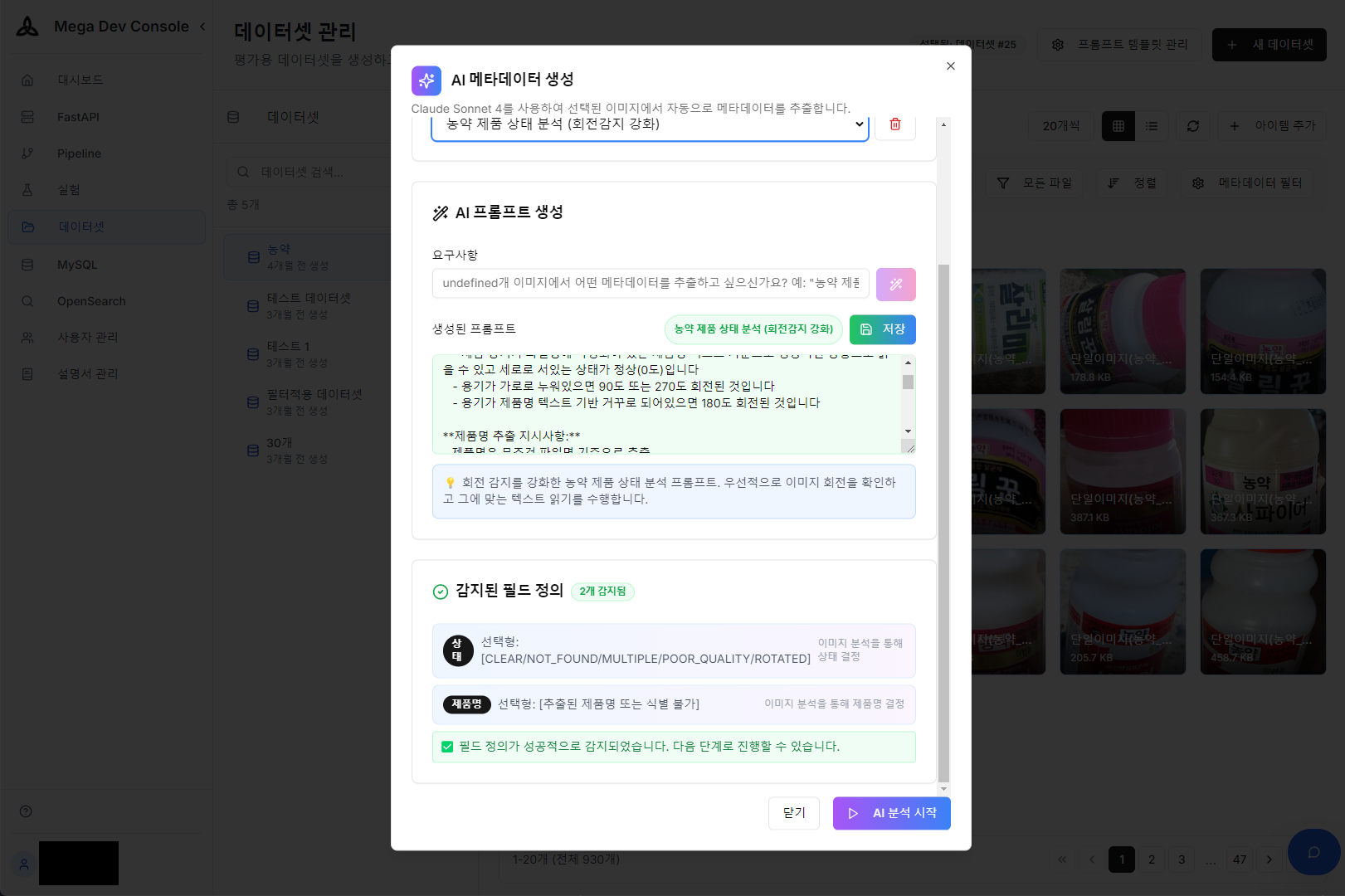
AI 프롬프트 빌더를 활용한 메타데이터 추출 프롬프트 설정
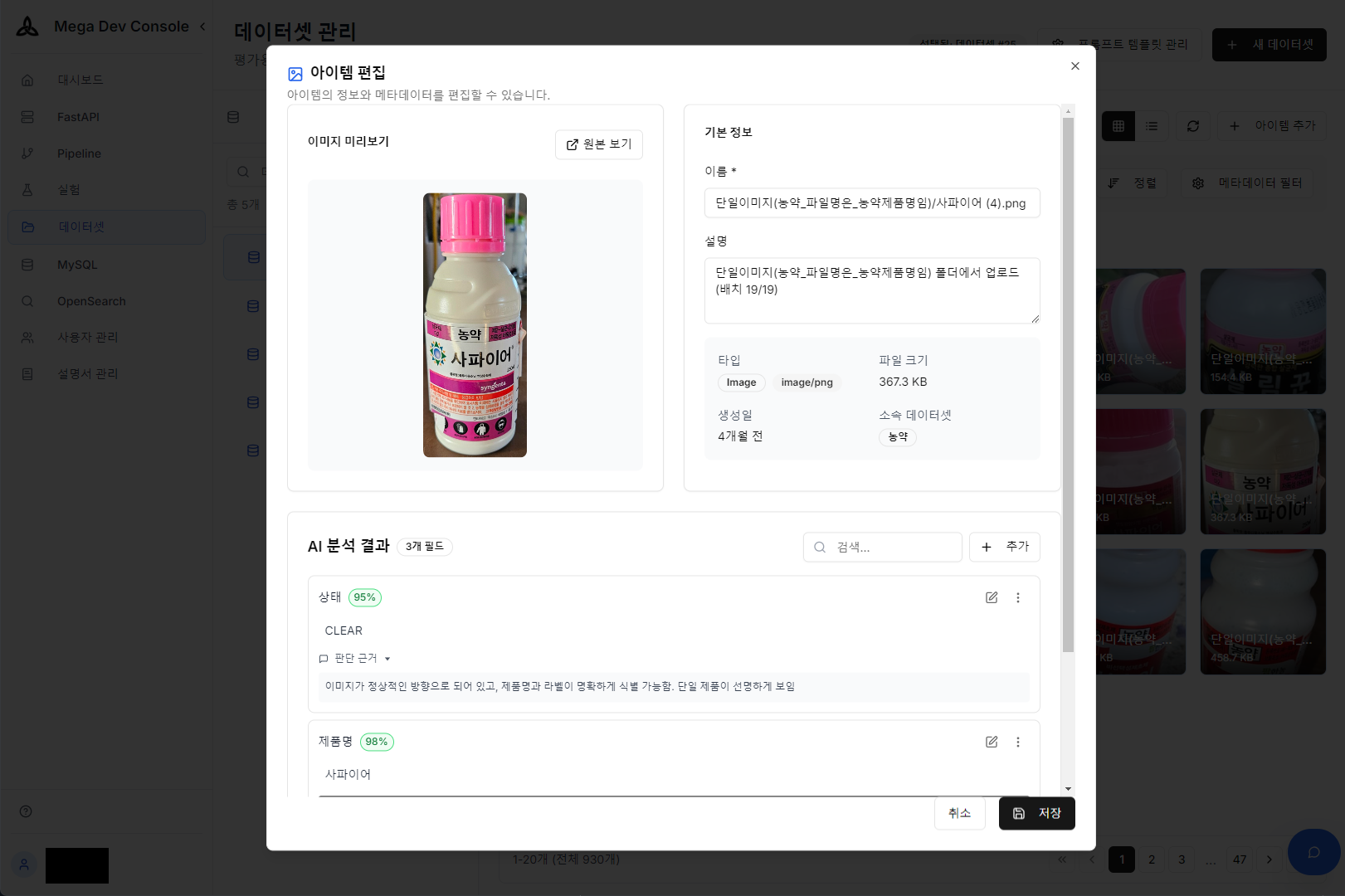
AI 분석 결과 — 제품 이미지에서 자동 추출된 메타데이터 확인
3. 자연어 기반 파이프라인 스케줄링
ETL 파이프라인 운영에서 가장 번거로운 것 중 하나가 크론(Cron) 설정입니다. “분기마다 새벽 3시에 실행해줘"와 같이 일상적인 언어로 입력하면, AI가 복잡한 Cron 표현식을 정확하게 생성하여 스케줄에 반영합니다. 운영자가 Cron 문법을 외울 필요가 없는 ‘Zero-Configuration’ 환경을 구현했습니다.
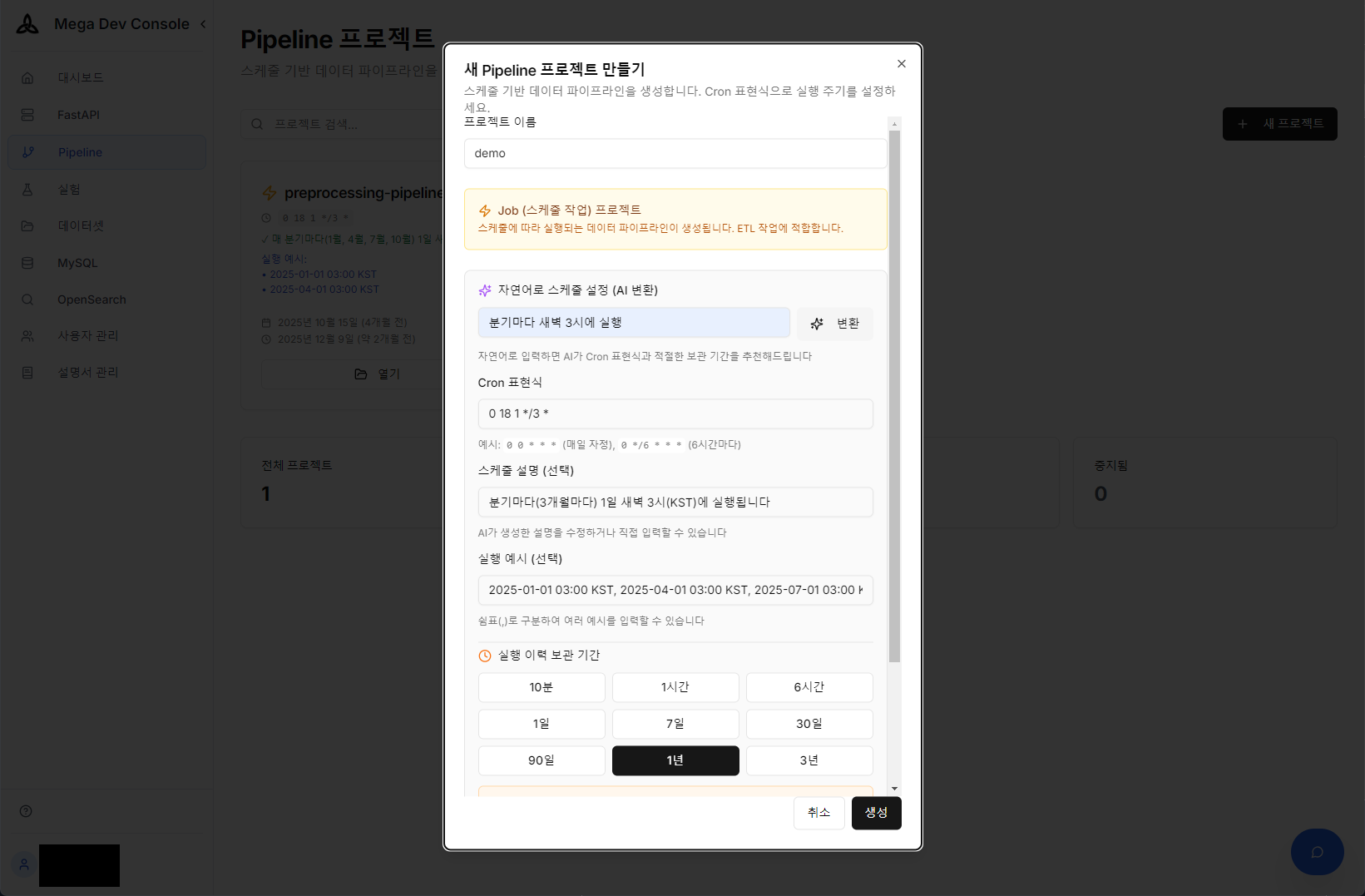
AI를 활용한 자연어 → Cron 표현식 자동 변환 및 파이프라인 스케줄 설정
4. OCR 실험실
배치 이미지에 대해 OCR 정확도를 정량적으로 측정하는 실험실을 구축했습니다. 모델이나 프롬프트가 변경될 때마다 대량의 테스트셋을 돌려보고, 정답 데이터와 비교하여 성능 변화를 즉각적으로 검증합니다.
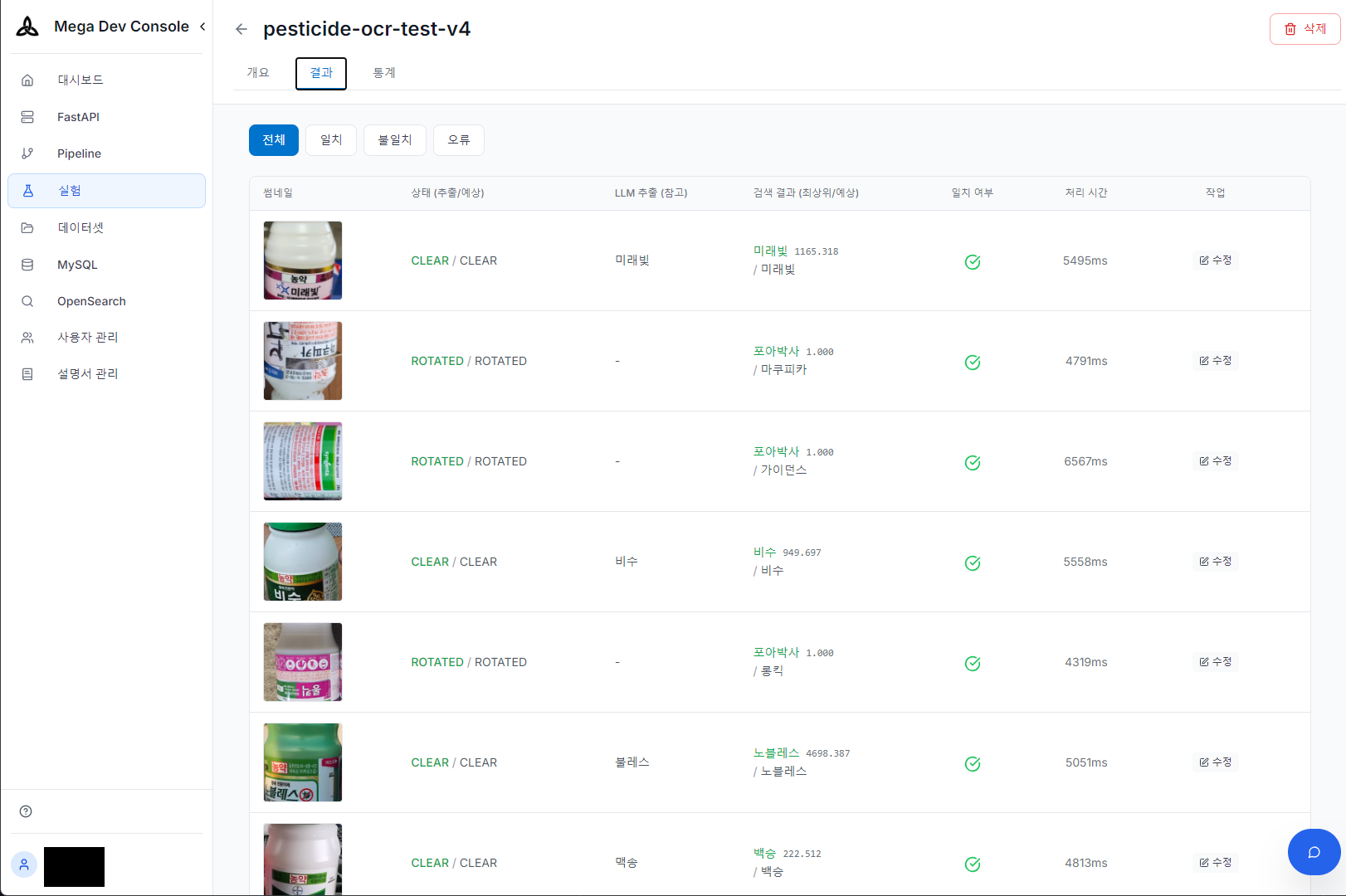
OCR 실험 결과 — 다양한 촬영 조건(정상/회전)에서의 추출·검색·일치 여부 확인
기술적 선택
Claude Haiku 4.5 vs Claude Sonnet 4.5: Vision LLM과 Reranker 모두 Claude Haiku 4.5를 선택했습니다. Sonnet 4.5가 정확도는 더 높지만, 농약 라벨 인식에서 Haiku는 대부분의 일반 촬영 조건에서 제품명을 정확히 추출했습니다. 응답 시간은 Haiku가 13초, Sonnet이 38초이고 비용 차이도 큽니다. 핵심은, TypoCorrector와 Reranker가 모델의 한계를 보완하는 구조이기 때문에 개별 모델의 정확도에 덜 의존한다는 점입니다.
OCR 앙상블(Ensemble) 시도와 최적화: 초기에는 인식률 극대화를 위해 전문 OCR 엔진의 결과를 Vision LLM에 힌트로 제공하는 방식을 검토했습니다.
- Upstage Document OCR: 인식률은 탁월했으나 API 비용 문제로 제외되었습니다.
- EasyOCR: 한글 인식은 준수했으나, 전체 파이프라인 레이턴시가 5~10초 이상 소요되어 모바일 UX에 부적합했습니다.
- Tesseract: 속도는 빨랐으나, 디자인된 폰트가 많은 농약 라벨 특성상 인식률이 현저히 낮았습니다.
최종적으로 외부 OCR 없이 Vision LLM 단독으로 사용하되, “가장 큰 텍스트” 같은 시각적 단서를 프롬프트에 주입하는 것만으로도 목표한 인식 품질과 평균 5초 내외의 응답 속도를 달성할 수 있었습니다. 코드에서는 환경변수 하나로 Sonnet 전환이 가능하도록 해두었습니다.
키워드 검색 vs 벡터 검색: 농약 제품명은 고유명사 위주이고, 등록번호(46-제초-546) 같은 식별자는 벡터 공간에서 의미 있는 거리를 가지지 않습니다. 의미적 유사도보다 문자열 유사도가 중요한 도메인이라, 키워드 검색(BM25)을 기본으로 사용하고 OCR 오류 대비용으로 wildcard Fallback을 보조적으로 두었습니다. 벡터 검색(Titan Embed Text v2)도 테스트했으나, 제품명과 등록번호의 정확한 매칭이 더 중요하다고 판단하여 최종적으로는 비활성화했습니다.
마치며
이 프로젝트에서 가장 중요한 교훈은, Vision LLM은 만능이 아니라는 전제 위에 시스템을 설계해야 한다는 것입니다.
실제 테스트에서 Vision LLM은 흐릿하거나 디자인 폰트가 강한 라벨에서 제품명을 잘못 읽는 경우가 적지 않았습니다. 하지만 1~2글자 수준의 오류 — “카네마이트"를 “가네마이트"로, “다이센45"를 “다이센엠45"로 — 는 TypoCorrector와 Fallback 검색이 대부분 보정하여, LLM 단독 대비 의미 있는 정확도 향상을 확인했습니다. 반면 제품명이 원형을 알아볼 수 없을 정도로 심하게 오인식된 경우에는 시스템 전체가 실패하며, 이는 향후 프롬프트 개선과 이미지 전처리로 풀어야 할 과제입니다.
벡터 검색(Embedding)이 오타 문제를 일부 해결해 줄 것이라 기대할 수 있지만, 실제로는 ‘바테스타’와 ‘바테스다’ 같은 고유명사의 미세한 차이가 벡터 공간에서 검색 가능한 수준으로 가깝게 매핑되지 않는 한계가 있었습니다. 결국 키워드 검색을 기반으로 하되, TypoCorrector부터 Reranker로 이어지는 다중 보완 구조가 OCR과 키워드 검색의 기술적 빈틈을 메우는 핵심이었습니다.
모델의 완벽함에 의존하기보다 시스템이 오차를 어떻게 복구하고 보완하느냐에 집중한 설계가 성능, 비용, 그리고 사용자 경험 사이의 최적점을 찾는 열쇠가 되어주었습니다.
