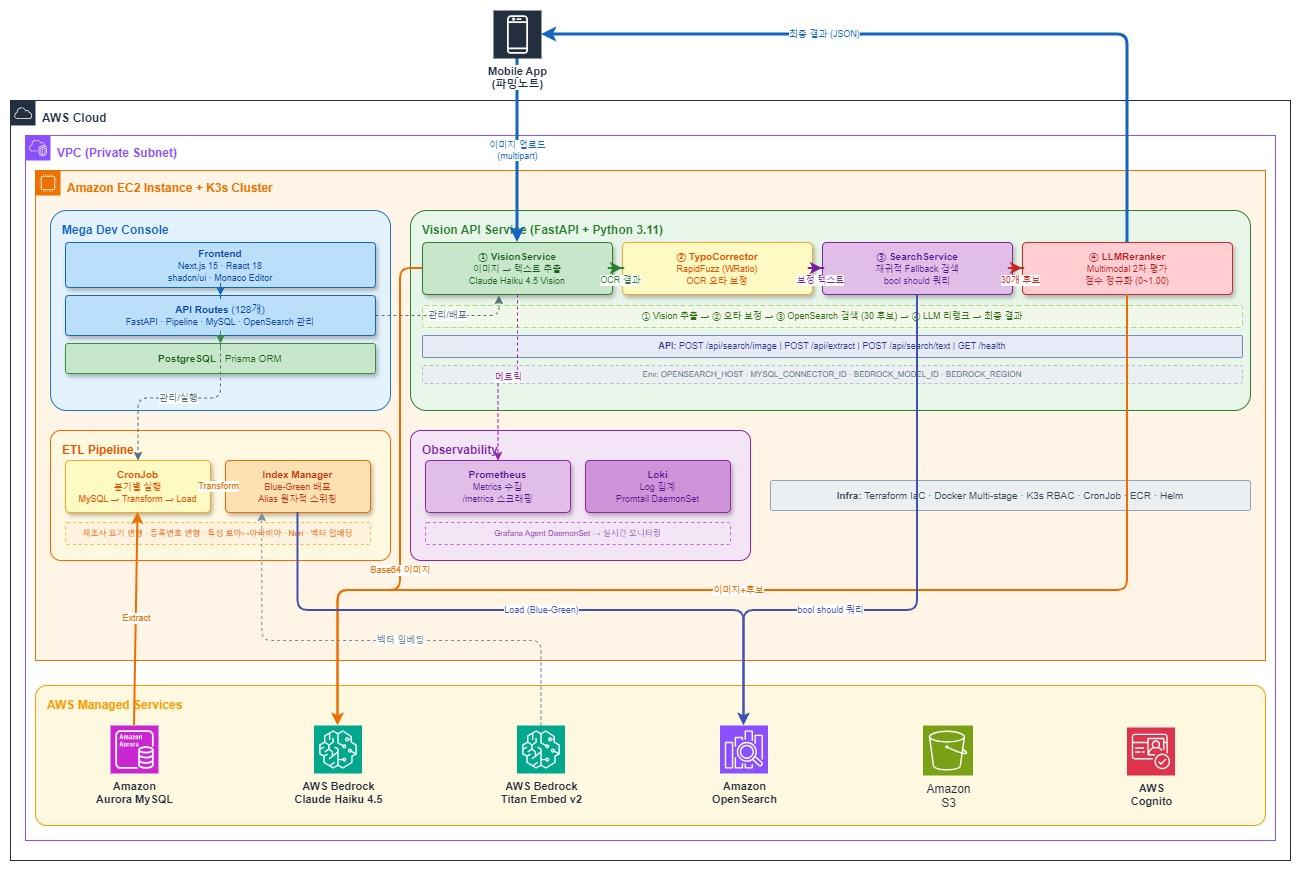
TL;DR: LLM에게 “어디부터 어디까지"만 묻고, 텍스트는 서버가 직접 꺼내면 됩니다. 3페이지 실측 기준 Output 토큰 90% 감소, 레이턴시 87% 감소, 비용 61% 절감. 배경: Docling에서 PyMuPDF + VLM으로 건축 법규 검토 AI를 만들면서, 건축 고시/지침 PDF를 의미 단위의 청크(chunk)로 나눠야 했습니다. RAG 파이프라인의 검색 단위로 사용하기 위해서입니다. 처음에는 IBM의 Docling을 사용했습니다. OCR 모델로 문서 구조를 파악한 뒤 청킹하는 방식인데, 두 가지 문제가 있었습니다: 무거움: OCR·레이아웃 분석 모델(RT-DETR 등)이 포함되어 Docker 이미지 크기와 처리 시간이 큼 커스텀 어려움: 내부 파이프라인이 블랙박스에 가까워, 건축 문서 특유의 계층 구조(장 > 조 > 항 > 호)나 표 처리를 세밀하게 제어하기 어려움 그래서 OCR 모델을 걷어내고 PyMuPDF로 텍스트와 폰트 메타데이터를 직접 추출하는 방식으로 전환했습니다. 구조 분석은 멀티모달 LLM(VLM)의 Vision 기능으로 대체하면 OCR 의존성을 완전히 제거하면서도 커스텀이 자유롭습니다. ...