LLMベースのPDFチャンキングでインデックス参照によりOutputトークン90%、レイテンシ87%を削減する
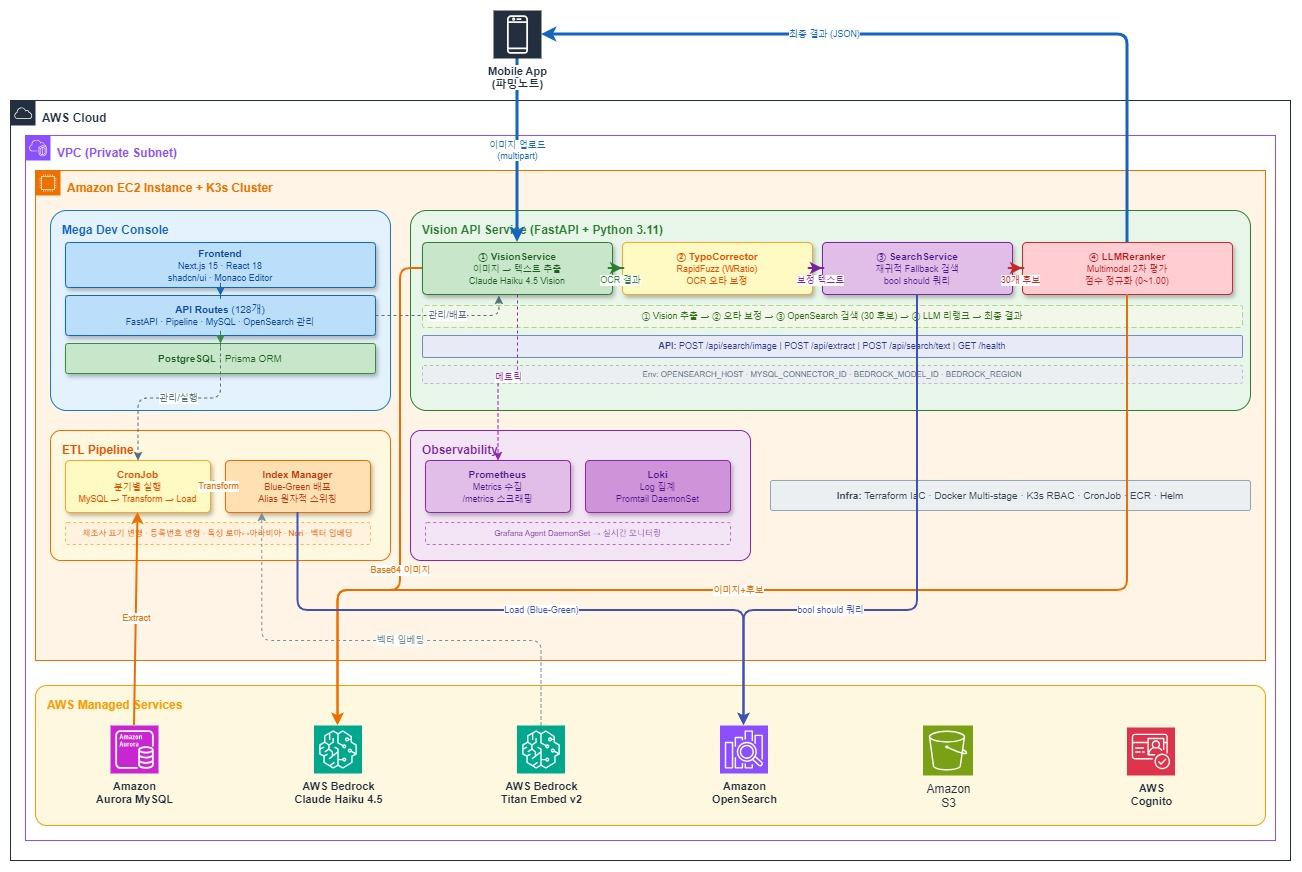
TL;DR: LLMには「どこからどこまで」だけを聞き、テキストはサーバーが直接取り出せばよいのです。3ページの実測値でOutputトークン90%削減、レイテンシ87%削減、コスト61%削減。 背景:DoclingからPyMuPDF + VLMへ 建築法規審査AIを開発する中で、建築告示・指針PDFを意味単位のチャンク(chunk)に分割する必要がありました。RAGパイプラインの検索単位として使用するためです。 当初はIBMのDoclingを使用していました。OCRモデルで文書構造を把握してからチャンキングする方式ですが、2つの課題がありました。 処理が重い:OCR・レイアウト分析モデル(RT-DETRなど)が含まれており、Dockerイメージサイズと処理時間が大きい カスタマイズが困難:内部パイプラインがブラックボックスに近く、建築文書特有の階層構造(章 > 条 > 項 > 号)や表の処理をきめ細かく制御しにくい そこでOCRモデルを排除し、PyMuPDFでテキストとフォントメタデータを直接抽出する方式に切り替えました。構造分析はマルチモーダルLLM(VLM)のVision機能で代替すれば、OCR依存を完全に排除しながらも自由にカスタマイズできます。 PDF → PyMuPDF テキスト抽出 → ページ分類 → LLM 構造分析 → チャンク生成 → エンベディング 以下は実際の処理対象である建築告示PDF — 大邱法院総合庁舎設計公募指針書の本文3ページです。 3ページ 4ページ 5ページ 「1. 公募の目的」「2. 事業の概要(가〜마)」「3. 公募要綱(가〜마)」など、階層的なセクション構造を持つ本文です。これをLLMが意味単位で自動分割するのが目標ですが、ここで新たな課題が発生しました。 課題:LLM Outputトークンのコスト LLM APIではOutputトークンの単価はInputの3〜5倍です。 モデル Input (/1M tokens) Output (/1M tokens) 倍率 Claude Haiku 4.5 $1.00 $5.00 5x Claude Sonnet 4.6 $3.00 $15.00 5x 最もシンプルなアプローチは、LLMに分割されたセクションの内容をそのまま再出力させることです。 ...