
仮想化ベースのEdgeデプロイ · Pub/Sub Payload制限回避 · 冪等性ベースの整合性確保
パイロット現場の突発変数とクラウドの限界を克服したMDE最適化プロセス
Cloud Tech Unit · GCP Delivery SA 3 Yoon Sung-jae | 2026-02-23
問題定義 — 泥沼の中のエンジニアリング
アーキテクチャ設計図がどれほど完璧でも、製造現場のラックマウントサーバーとネットワークケーブルの前では無力になることがあります。前回の記事で「優雅な」アーキテクチャを紹介しましたが、今回はパイロット期間中に現場エンジニアが全力で立ち向かった泥沼のようなトラブルシューティングの過程を紹介します。
本記事では、パイロット運用報告書に記録された3つの激しい問題解決プロセスを包み隠さず共有します。
Challenge 1:ハードウェア互換性とエッジデプロイの悪夢
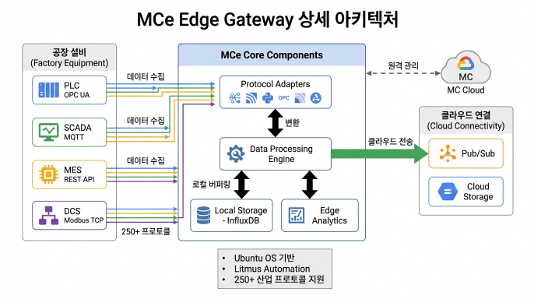
ベアメタルマルチディスク(RAID)ボリューム構成の制約
工場現場に配置されたDell物理サーバー(ベアメタル)にエッジゲートウェイであるMCe(Manufacturing Connect Edge)OSを直接インストールしようとした際に直面した問題です。
現場のDellサーバーは、エンタープライズ環境の安定性と容量を確保するためにOS領域(ミラーリングされたディスク2台)とデータ格納領域(RAID 5構成のディスク4台)、計2つの論理ドライブ(パーティション)で構成されていました。しかしMCeの公式デプロイイメージは、インストール時にシングルパーティション(Single Volume)構成のみを対応するという制約がありました。そのため、2パーティションに分離された現場サーバーのストレージアーキテクチャをMCeが受け入れられず、ベアメタルへの直接インストールが不可能な状況でした。
仮想化(Virtualization)によるハードウェアデカップリング
ハードウェアパーティションの制約をソフトウェア的に解決するため、ベアメタルへの直接インストールを断念し、仮想化レイヤーを挿入する戦略に転換しました。
- 物理サーバーにマルチパーティションおよびハードウェアドライバー互換性に優れたUbuntu OSをまずインストールし、ハードウェア制御権を汎用OSに委譲しました。
- その上にVirtualBoxベースの仮想環境を構成し、仮想マシン(VM)に単一の仮想ディスクを割り当ててMCeイメージをデプロイしました。
この回避策は初期セットアップの制約を突破しただけでなく、エッジに問題が発生した際にVMスナップショット(Snapshot)によって5分でシステムをロールバックできる優れた運用柔軟性(Resilience)ももたらしました。
Challenge 2:大容量データ処理の限界とPub/Sub Payload制限の克服
エッジOOM(Out of Memory)とクラウドの物理的限界
工場のデータはセンサーログだけではありません。収集対象にはファイル1つが2GBを超える巨大なCSVファイルや、高解像度の品質検査画像(JPG、BMP、PNG)、工程映像(MPG、MP4)も含まれていました。
ここで2つの物理的限界に直面しました。第一に、初期の標準パイプラインフローに従い2GB以上のCSVファイルを一括でメモリにロードしてシリアライズしようとしたところ、MCeエッジ側でOOM(Out of Memory)が発生しました。第二に、Google Cloud Pub/Subのメッセージあたりの最大許容サイズ(Payload Limit)は10MBに制限されており、大容量データを直接ストリーミングで送ること自体がアーキテクチャ上不可能でした。
ツートラック(Two-Track)解決戦略:ChunkingとClaim-Check
この問題を解決するため、エッジレベルのデータ処理方式とクラウド転送アーキテクチャの両方を修正するツートラック戦略を採りました。
1. MCeレベルのチャンク(Chunk)単位分割ローディング
2GB以上の大容量CSVファイルは、ファイル全体を一括でメモリにロードする既存方式を廃止しました。代わりにMCe収集フロー(Flow)内部でファイルを複数の小さなチャンク(Chunk)に分割し、逐次的(Incremental)にロード・処理する方式に変更し、エッジ側のOOM問題を根本的に解消しました。
2. Claim-Checkアーキテクチャパターンの適用
クラウドメッセージング環境で大容量ペイロードを処理するための標準アーキテクチャであるClaim-Checkパターンを適用し、パイプラインフローを2系統に分離しました。
| データタイプ | サイズ | 転送経路 | 動作方式 |
|---|---|---|---|
| Telemetry(センサー) | 10MB未満 | MCe → Pub/Sub | 標準JSONシリアライズ後にリアルタイムストリーミング転送 |
| Large Files(大容量画像・映像) | 10MB以上 | MCe → GCS | 原本ファイルをCloud Storage(GCS)バケットに直接アップロード |
大容量ファイルの場合、Edgeは実際のデータの代わりに「GCSファイルパス(URI)とメタデータ」のみを含む数KBの軽量メッセージ(Claim-Check Token)だけをPub/Subに送信します。その後Dataflowがこのメッセージをサブスクライブすると、該当URIを参照してGCSから直接データを並列で読み取り処理することで、Pub/Subのネットワークボトルネックを完全に解消しました。
Challenge 3:データ整合性のジレンマ(なぜ数字が合わないのか?)
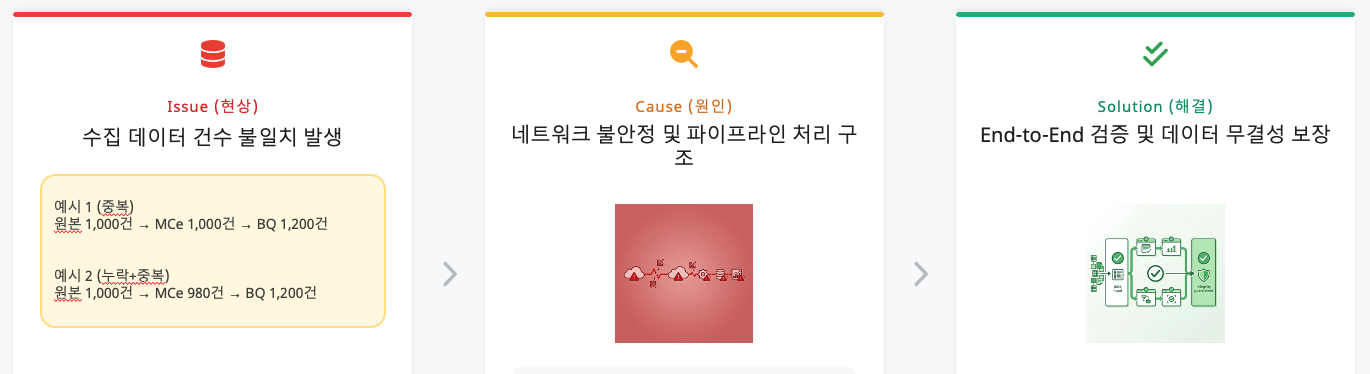
問題状況:データエンジニアの悪夢
最後まで私たちを悩ませた課題は**「収集データ件数の不一致」**でした。
例:原本CSVファイルのレコード数は1,000件なのに、エッジ(InfluxDB)には980件しか格納されず(欠損)、最終到達先のBigQueryには1,200件が格納される(重複)現象。
深層原因分析:重複と欠損の二重奏
デバッグの結果、データが増減した原因はそれぞれ異なる箇所にありました。
1. 重複(Duplication)の原因:BigQueryと手動介入
BigQueryはデータ受信時に重複チェックを行わず無条件に格納(Append-only)する特性があります。これに加えてパイプライン検証のためにエンジニアがPub/Subにデータを手動注入したり再送テストを繰り返したりすることで、物理的なデータ量が膨張しました。
2. 欠損(Loss)の原因:原本データの重複とMCのフィルタリング
より深刻な問題は「消えたデータ」でした。分析の結果、現場から提供された原本CSVファイル自体に、同一タイムスタンプと値を持つ重複データが含まれていました。**MC(Manufacturing Connect)エッジはこれを「同一データ」と正確に判断し、重複送信を防ぐために自らフィルタリング(Drop)**していました。結果としてシステムは正常に動作していましたが、原本ファイルの物理的な行数と格納されたデータ数の不一致を招き、「欠損」と誤認させる原因となりました。
解決アプローチ:DLQと冪等性保証
これらの整合性問題に対処するため、MDEソリューションが提供するDead Letter Queue(DLQ)機能と冪等性(Idempotency)保証オプションを活用する戦略を策定しました。
- UUIDベースの冪等性: データ生成時に固有ID(UUID)を付与することで、同一データが再送信されても重複格納を防止します。
- DLQによるエラー隔離: 処理に失敗したデータを別キューに隔離し、メインパイプラインの整合性を保護しつつ、後続の分析および再処理のためのセーフティネットを確保します。
- BigQuery重複排除: 格納後も
MERGEまたはROW_NUMBER()ベースのDeduplicationクエリにより、最終データの一意性を保証します。
核心的教訓
今回のPoCは279TBという巨大なデータをクラウドへ移行するプロセスでしたが、私にとっては机上で描いたアーキテクチャが現場の泥沼の中でどのように崩壊し再構築されるかを目撃した時間でした。このプロジェクトを通じて学んだ3つの教訓を共有します。
現場のハードウェアは常に予想を裏切る(Flexibility over Performance)
「標準サーバーだから当然インストールできる」という安易な考えは、現場のレガシーRAIDコントローラーの前で打ち砕かれました。エンジニアリングの世界でベアメタルの性能最適化は魅力的ですが、変数が制御できないエッジ(Edge)環境では**「柔軟性(Flexibility)」こそが「生存(Survival)」**であることを学びました。仮想化レイヤーを1枚追加することはオーバーヘッドではなく、予測不可能なハードウェア問題からソフトウェアを守る最も確実な保険でした。
クラウドの限界を認めた時に真の設計が始まる(Design for Limits)
無限に見えるクラウドリソースにも結局は物理的な制限(Quota)があります。Pub/Subの10MB制限やエッジデバイスのメモリ不足(OOM)に直面した時、単にリソース増量を要求するのは初心者の発想です。この制約を認め、Claim-CheckやChunkingといったアーキテクチャパターンで迂回路を切り開きました。真のエンジニアリングは制約のない環境ではなく、制約の中で最適解を見出す時に輝きます。
整合性は設計の第一ボタンである(Consistency First)
大規模データパイプラインにおいて整合性は付加機能ではなく、コア設計要素です。原本データの重複や手動テスト過程での副産物が混在すると、データの信頼性が急激に低下します。**データ完全性の検証は「事後処理」ではなく「設計の第一ボタン」**です。冪等性(Idempotency)保証とDLQ設計をパイプラインコアに内蔵することが、279TB級の大規模収集システムの成功を左右する核心要素です。
今回のPoCで荒削りな異種データが流れることのできる「巨大で堅牢なパイプライン」を建設し、冪等性・DLQベースのデータ整合性セーフティネットまで設計しました。この経験を基に、AIモデルが安心して利用できる**1級水(High-Quality Data)**を安定的に供給することが製造AIパイプラインの究極的目標です。
付録:Manufacturing Connect Edge(MCE)インストールおよび構成ガイド
このガイドは、ベアメタルサーバーのインストール難易度を解決するためのPINN PoCプロジェクト(韓国)専用の設定方式であることにご注意ください。実際の本番環境でのインストール手順はこれとは異なる場合があります。
MC(Manufacturing Connect)とMCEのインストールには、物理ハードウェア、クラウド環境、予算など準備すべき事項が多く、実際のインストールとテストが難しい場合があります。以下に整理した手順が全体的な流れを理解する上で参考になれば幸いです。
ディスク構成は以下の通りです。
/dev/sda:300GB。RAID 1(ミラーリング)構成。Ubuntu OSインストール領域。/dev/sdb:32TB。RAID 5構成。InfluxDBデータ格納領域。
Ubuntu Linuxのインストールとネットワーク設定
最初に基本オペレーティングシステムであるUbuntuをインストールし、ネットワークを構成します。
- OSインストール: 起動可能なUSBから「Try or Install Ubuntu」を選択してインストールを進めます。
- ネットワーク設定: 「Advanced Network Connection」でIP、ゲートウェイ、サブネットマスク、DNSを設定します。
- ファイアウォール有効化: セキュリティのためUFWファイアウォールを有効にします。
# ファイアウォール有効化
sudo ufw enable
システムアップデートとデータディスクフォーマット(32TB)
システムを最新の状態に保ち、大容量ハードドライブをパーティショニングします。
# システムアップデート
sudo apt update
# ディスク確認および既存パーティション削除
sudo lsblk
sudo wipefs -a /dev/sdb
sudo sgdisk --zap-all /dev/sdb
# GPTパーティション作成(Parted使用)
sudo parted /dev/sdb
# (partedプロンプト進入後)
mklabel gpt
mkpart primary ext4 0% 100%
print
quit
# ファイルシステムフォーマット(EXT4または必要に応じてXFS)
sudo mkfs.ext4 /dev/sdb1
# または sudo mkfs.xfs /dev/sdb1
# マウントおよび自動マウント設定
sudo mkdir -p /mnt/data
sudo mount /dev/sdb1 /mnt/data
# UUID確認後、/etc/fstabに追加して再起動時に自動マウント
sudo blkid /dev/sdb1
# 例:UUID=abcd-1234 /mnt/data ext4 defaults 0 2
VirtualBoxのインストールとKVM無効化
MCEは仮想環境で実行されるため、VirtualBoxをインストールします。この際、競合防止のためKVMモジュールを必ず無効化する必要があります。
# VirtualBoxインストール
sudo apt install virtualbox
# 現在のセッションからKVMモジュールを削除(Intel CPUの場合)
sudo modprobe -r kvm_intel
# KVM永続ブラックリスト追加
sudo nano /etc/modprobe.d/kvm.conf
# ファイル内に 'blacklist kvm_intel' と入力して保存
# カーネルイメージ更新および再起動
sudo update-initramfs -u -k all
sudo reboot
MCE(Manufacturing Connect Edge)のインストールと自動起動設定
ISOイメージからMCEをインストールした後、サーバー再起動時にVMが自動的に起動するよう設定します。
- インストールガイド: Litmus Edge VirtualBoxインストールドキュメントを参照してください。
- 自動起動設定: 「Startup Applications」ユーティリティに以下のコマンドを追加します。
# VM自動実行コマンド(Headlessモード推奨)
VBoxManage startvm "ユーザー_VM名" --type headless
ホスト設定とMCの有効化
管理コンソール(MC)へのアクセスのためのドメインおよびIP設定を行います。
/etc/hostsファイルにmz.co.krを追加します。mz.co.krにアクセスしてパスワードを変更します。- Admin UI > Settings > Entry Pointsでドメインを MCのプライベートIPに変更します(反映まで約8分かかります)。
- JSON SAキーをアップロードし、MCEを有効化します。
最終確認事項
すべての設定が完了したら、サーバーを再起動して以下を確認してください。
- MCE(Manufacturing Connect Edge)が自動的に起動するか?
