
250以上の産業プロトコル対応 · Edge-to-Cloudパイプライン · 物理レベルのプロジェクト分離
セキュリティとコストのトレードオフを考慮したManufacturing Data Engine実践構築記
Cloud Tech Unit · GCP Delivery SA 3 Yoon Sung-jae | 2026-02-23
事業背景 — PINNモデル基盤の融合データプラットフォーム
製造業のデジタルトランスフォーメーション(DX)における最大のハードルは、現場のITとOTデータをクラウドへ安全かつシームレスに移行する「ラストマイル(Last Mile)」にあります。
本記事は、韓国政府主導で進められた「2025年PINN(Physics-Informed Neural Networks)モデル製造融合データ収集・実証事業」のクラウドインフラパートナーとして、8つの製造企業の異種データをGoogle Cloud Manufacturing Data Engine(MDE)基盤で統合構築した事例を紹介します。
当初の事業計画書における収集目標は185TBでしたが、250以上の産業プロトコルに対応する高性能パイプラインを構築し、目標比150%を超える合計279TBの製造データ(時系列センサー、画像、映像など)の収集に成功しました。本記事では、その巨大なデータダムを構築するために徹底的に議論したアーキテクチャ意思決定(ADR)を共有します。
問題定義 — OT-IT融合の3つのジレンマ
PINNモデルの学習を成功させるには、高品質の生データ(Raw Data)が不可欠です。しかしプロジェクトの核心である**「IT-OT融合」**を実現するには、まず両領域のデータが持つ性質と違いを理解する必要がありました。
- IT(情報技術)データ: ERP、MESなど業務を支援する経営システムから生成されるデータ
- OT(運用技術)データ: PLC、SCADAなど物理的な設備を制御し生産を担う現場技術から生成されるデータ
この2つの領域を統合する過程で、以下の現実的な障壁に直面しました。
断片化された設備環境とプロトコル(Heterogeneous Environment)
8つの工場はそれぞれ異なる機器を使用していました。IT領域ではERP、MESなどのシステムごとに使用中のデータベースが異なり、OT領域も工場ごとに導入した設備メーカーが異なっていました。さらに収集対象のデータフォーマットも、CSV、JSON、Parquetなどの構造化データから画像(JPG、PNG、BMP)、映像(MPG、MP4)などの非構造化データまで混在しており、これらを網羅する標準化された収集体系の策定は非常に困難でした。
ネットワーク帯域幅の限界とデータ欠損リスク(Network Reliability)
製造現場のネットワーク環境は、大容量データをクラウドに転送するには不十分でした。外部インターネット接続は回線の冗長化が行われておらず、既存の内部業務ネットワークと回線を共有していたため、慢性的な帯域幅不足が発生していました。ネットワーク遅延や切断が発生した場合でも、データはエッジ側で安全にバッファリングされ、ネットワーク復旧時に欠損なく順序通りクラウドに転送できる堅牢なアーキテクチャが必要でした。
厳格な企業間データ分離(Strict Multi-Tenancy)
参加する8つの製造企業は潜在的な競合関係にある可能性があります。クラウドという「共有リソース」を使用しながらも、企業間のデータ混入懸念を完全に払拭する物理レベルの論理的分離(Isolation)がプロジェクト成功の鍵でした。
全体アーキテクチャ — Edge-to-Cloud Pipeline
上記の問題を解決するため、Google Cloudの特化ソリューションであるMDE(Manufacturing Data Engine)とMC(Manufacturing Connect)をコアとして採用しました。全体アーキテクチャは「現場設備に影響を与えない」という大原則の下、4つのLayerで設計されました。
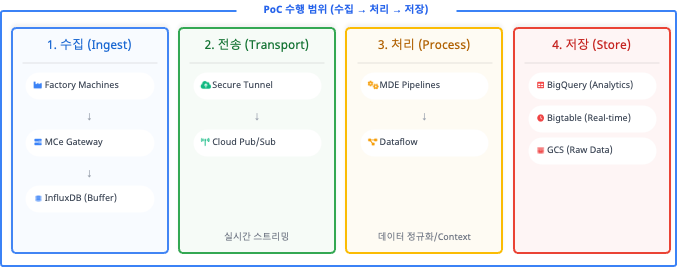
| Layer | コンポーネント | 主な役割 |
|---|---|---|
| Edge | MCe(Manufacturing Connect Edge) | 現場ネットワーク内に配置。250以上のプロトコルに対応。ネットワーク切断時はInfluxDBを活用したエッジローカルバッファリングを実行 |
| Transport | Cloud Pub/Sub | 毎秒数百万件のイベントを処理する大容量非同期ストリーミング。トラフィックスパイク時のシステムダウンを防ぐバッファーゾーンとして機能 |
| Processing | Cloud Dataflow | リアルタイムデータ正規化(Normalization)。センサー値に設備名・ライン位置などのメタデータを結合(Contextualization)してビジネス価値を付与 |
| Storage | BigQuery / Bigtable / GCS | ラムダアーキテクチャ(Lambda Architecture)を採用。大規模分析用BQ、リアルタイムクエリ用BT、大容量ファイル用Cloud Storageに分散格納 |
核心的意思決定 — セキュリティとコストのトレードオフ
クラウドアーキテクトとして最も悩んだのは「マルチテナンシー(Multi-tenancy)環境をどう設計するか」でした。収集対象が8つの異なる(しかも潜在的競合関係にある)企業だったため、データ分離レベルに関するアーキテクチャ上の決定が必要でした。
代替案A:単一プロジェクト内のデータセットベース分離(Dataset-level Isolation)
1つの統合GCPプロジェクト内にすべての工場のデータパイプライン(Pub/Sub、Dataflowなど)を集中化し、データが格納される最終ストレージ(BigQuery)段階でのみ「工場別データセット(Dataset)」を作成して論理的に分離する方式です。
- メリット(Pros): インフラリソースを8工場で共有するため、コンピューティングリソースの無駄を防ぎ、コスト最適化(Cost Efficiency)に非常に有利です。また単一ポイントからパイプラインの監視とデプロイメントを実施でき、運用管理効率が高くなります。
- デメリット(Cons): 複数企業のデータが同一メモリ(Dataflowワーカー)とキュー(Pub/Sub)を経由するため、IAM権限設定やパイプラインコードの微細な誤設定(Misconfiguration)により、他企業のデータが混入・漏洩する潜在的セキュリティリスクが存在します。
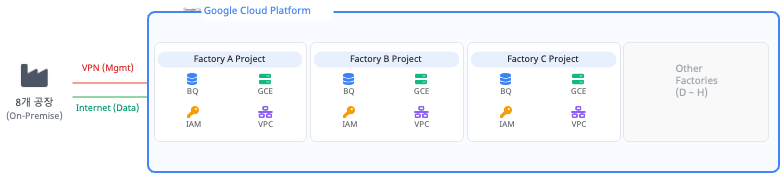
代替案B:工場別独立プロジェクトベース分離(Project-level Isolation)
8工場それぞれに完全に独立したGCPプロジェクトを割り当てます。工場ごとに固有のVPCネットワーク、Pub/Sub、Dataflowワーカー、BigQueryインスタンスを個別に構築し、収集から格納までのすべてのデータフローを物理的に遮断する方式です。
- メリット(Pros): プロジェクト単位で境界が完全に分離されるため、データ混用の可能性を根本的に排除でき、セキュリティとデータ独立性が最大化されます。プロジェクト単位のIAM権限付与によりアクセス制御が明確になり、課金(Billing)もプロジェクト別に明確に分離されて透明性を確保できます。
- デメリット(Cons): 同一インフラ(VPC、ロギング、パイプラインなど)を8セット稼働させる必要があり、維持コスト(TCO)が大幅に増加します。データ流入量の少ない工場にも固定のDataflowワーカーが割り当てられ遊休リソースが発生し、8つの環境を個別にパッチ・監視する必要があるため運用管理の複雑性が非常に高くなります。
Architect’s Note: 初期設計段階では拡張性とコスト効率性(代替案A)の魅力が大きかったです。しかし政府実証事業の特性上、参加企業のセキュリティ懸念(競合他社間のデータ漏洩)を根本的に排除することがプロジェクト成否の鍵でした。最終的にコスト効率性と運用利便性を大きく犠牲にしても、物理レベルの分離を提供するProject-level Isolation(代替案B)を採用しました。
ネットワークセキュリティ — 伝送網の二元化
製造(OT)ネットワークの閉鎖性を尊重するため、ネットワークトラフィックを二元化しました。
- Management Traffic: MC中央サーバーからエッジ(MCe)にデプロイされるファームウェアアップデートおよび構成(Configuration)管理は、VPN(Private)トンネルを通じてのみ実施するよう制御しました。
- Data Traffic: テラバイト規模のセンサーデータはVPN帯域幅では処理できないため、TLS暗号化されたパブリックインターネット回線を通じてGCP Pub/Subエンドポイントに直接転送するよう分離設計しました。
核心的教訓
完全な分離の代償とコスト最適化の必要性
徹底したプロジェクト分離はセキュリティ面では優れていましたが、各工場ごとにDataflowワーカーとモニタリング環境が重複作成され、多くの遊休リソース(Idle Resource)が発生しました。今後の本事業拡張時には、Shared VPCを基盤にインフラを共有しつつデータのみ論理的に完全分離するハイブリッドアプローチを導入する必要があります。
データガバナンス標準化の重要性
同じ「温度」データでもA工場はtemp_1、B工場はtemperature_valと命名規則が異なっていました。統合PINNモデル学習のためには、データ収集前の段階でスキーマ標準化および全社メタデータ辞書に関するルールセットを策定することが核心です。
AIと分析のための次のステップ
今回のPoCは融合データが安全に流れることのできる強力な「高速道路」を開通させたものです。今後の本事業では、収集されたデータを基にLookerダッシュボードによる可視化とVertex AIベースの予知保全PINNモデル開発という真のビジネス価値創出段階へ進みます。
