(株)慶農ファーミングノート高度化プロジェクト — 農薬製品の写真1枚で製品情報を自動検索するAIシステムの設計と実装過程を共有します。
プロジェクト背景
慶農は以前、AWS、メガゾーンクラウドと共に生成型AI基盤の農業専門チャットボットを構築していました。Amazon Bedrock Claude Sonnet 3.5とOpenSearchを活用したRAGアーキテクチャで、農業者が自然言語で質問すると作物保護剤情報を自動で応答するサービスでした。
このチャットボットを運営する中、慶農から現場の意味のあるフィードバックと新しい提案を受けました。高齢の農業者が多い現場特性上、スマートフォンで長くて馴染みのない農薬製品名を直接タイピングするのは非常に煩わしいという点でした。
「現場でスマートフォンで製品を撮影するだけで情報をすぐに見つけられないか?」 — お客様のこのような悩みを基に、テキスト入力を超えた視覚的検索システムを構築する高度化プロジェクトが始まりました。
問題は単純ではありませんでした。現場で撮った写真はぼやけていたり回転していたりし、韓国語・数字・特殊文字が混在したラベルからVision LLMがテキストを完璧に読み取るのは困難です。約4,000種の類似した製品名の中から「バテスダ」が「バテスタ」の誤認識なのか全く別の製品なのかを区別する必要があります。そのためOCRが間違っても製品を見つけるシステムを作る必要がありました。
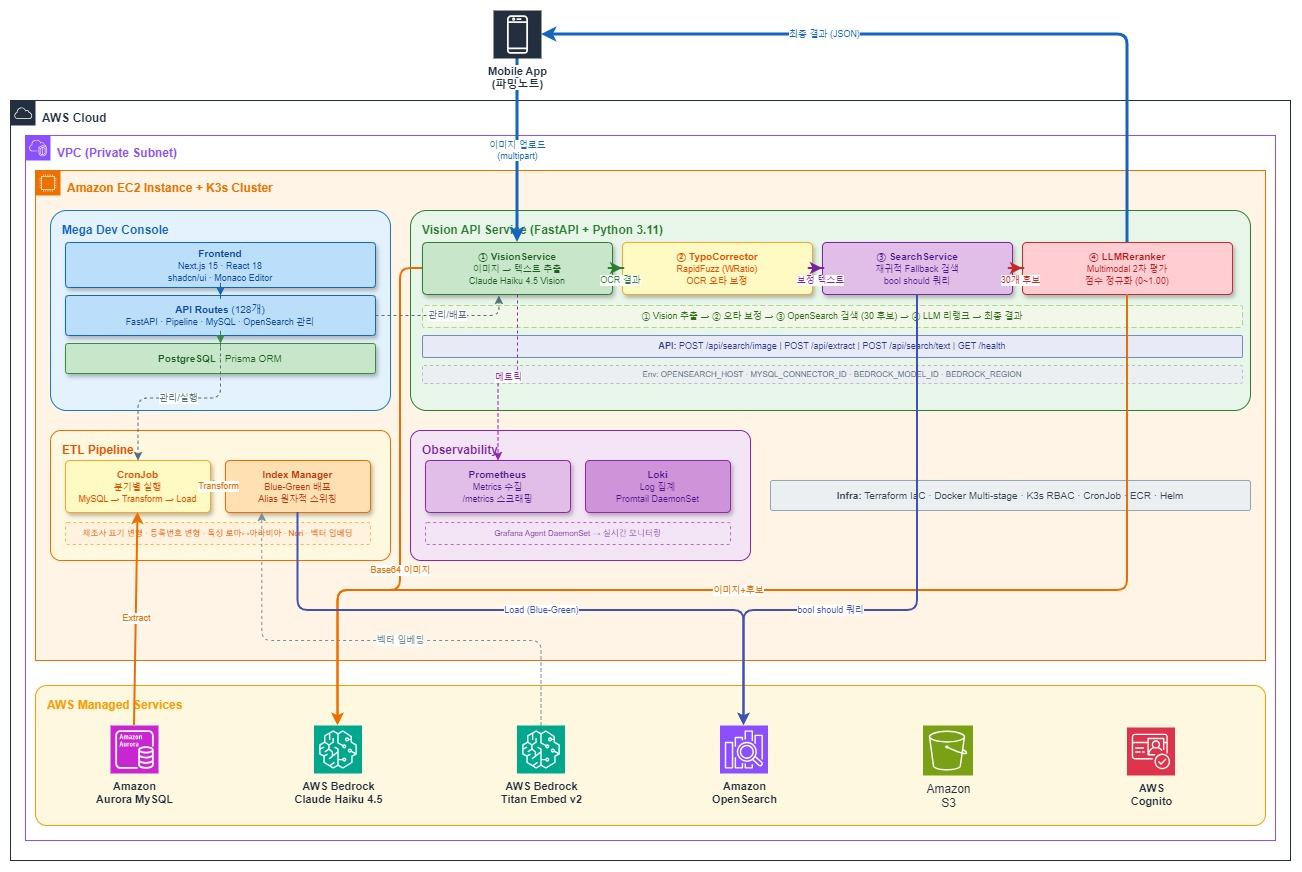
システムアーキテクチャ

システムアーキテクチャ — AWSマネージドサービス連携
ユーザーが農薬製品画像をアップロードすると、システムは3段階を順次実行します。各段階は前段階の不完全さを補完するよう設計されています。
Stage 1 — Vision LLMがラベルを読み(製品名、登録番号、製造社抽出)
TypoCorrectorがOCRタイポを補正
Stage 2 — OpenSearchが階層的フォールバックで候補群を検索
(完全一致から部分マッチングまで1回のクエリで)
Stage 3 — LLM Rerankerが元の画像を再度見て最終順位を決定
この記事の残りの部分では各段階を詳細に扱います。
OCRが間違っても製品を見つける方法
Vision LLM:ラベルから情報抽出
画像からテキストを抽出するのは一般的なOCRとは異なります。単にテキストを読むのではなく、「農薬製品ラベル」というドメイン知識を基に構造化された情報を抽出する必要があります。
圧縮JSON戦略
Vision LLMの応答速度を最適化するため、出力トークンを最小化する圧縮JSONフォーマットを設計しました:
LLMが返す圧縮形式:
{"s":"C","n":"バテスタ","g":"46-除草-546","m":"ファームハンノン","i":"メトラクロル粒剤","c":{"n":0.95,"g":0.9,"m":0.9,"i":0.85}}
サーバーで標準形式に変換:
{
"status": "CLEAR",
"product_name": "バテスタ",
"registration_number": "46-除草-546",
"manufacturer": "ファームハンノン",
"ingredient_name": "メトラクロル粒剤",
"confidence": {
"product_name": 0.95,
"registration_number": 0.9,
"manufacturer": 0.9,
"ingredient_name": 0.85
}
}
max_tokens: 500、temperature: 0.0に設定して決定論的で簡潔な出力を誘導します。すべてのフィールドに0.0〜1.0の信頼度を一緒に返してもらい、後続処理を動的に調整します。信頼度が中間水準のフィールドにはタイポ補正を試み、補正後も信頼度が低いフィールドは検索クエリから除外して誤検索を防ぎます。
プロンプトによるデザインテキスト認識克服
農薬製品名は注目度を高めるため華やかなカリグラフィや独特なタイポグラフィでデザインされることが多いです。初期テストではVision LLMがこれらのデザインされた文字をテキストではなく絵として誤認する場合がありました。私たちはプロンプトに**「製品名はラベルで最も大きく目立つテキスト(largest text)である」**という視覚的コンテキストを明示的に提供しました。この簡単な指示だけでモデルは視覚的レイアウト内での重要度を把握するようになり、複雑にデザインされた製品名もテキストとして正確に抽出し始めました。
画像状態分類
テキストを抽出する前に、まず画像自体の状態を診断します。CLEAR(正常)、ROTATED(回転)、MULTIPLE(複数製品)、NOT_FOUND(製品未検出)の4つの状態を分類し、CLEARでない場合はユーザーに再撮影を案内します。この時、同一製品複数個(例:モベント3本)はCLEARとし、異なる製品が一緒にある時のみMULTIPLEとして処理します。
登録番号抽出の難しさ
農薬登録番号は数字-用途-数字形式(例:46-除草-546)に従いますが、ラベル上で位置が一定でなく「H5」「H8」のような危険物コードと混同されやすいです。プロンプトに区別基準を明示しました:
* Format: number-[殺虫|除草|殺菌]-number (例: "46-除草-546")
* "H5", "H8"などが見えてもそれはハザードコードであり、登録番号ではありません
* 登録番号の中間部分は必ず殺虫、除草、または殺菌です
TypoCorrector:OCRタイポ補正
Vision LLMがいくら優秀でも、ぼやけたり部分的に隠れたラベルでは誤認識が発生します。「バテスタ」を「バテスダ」と、「ファームハンノン」を「ファームハンロン」と間違って読むことがあります。このタイポをそのまま検索クエリに入れると検索が失敗します。
サーバー起動時にOpenSearchから全製品名(約4,000個)と製造社(約200個)をメモリにキャッシュしておき、RapidFuzzライブラリのWRatioスコアラーを使用します。WRatioは複数の類似度測定方式を組み合わせて最適なスコアを返すため、「バテスダ」のように1〜2文字が間違っていたり製品名が一部だけ読まれた場合でも元の製品名をマッチングするのに効果的です:
# 製品名:threshold 75(寛大に — タイポが多い可能性があるため)
result = process.extractOne(
input_name, # OCR結果:"バテスダ"
self.product_names_cache, # 実際の製品リスト
scorer=fuzz.WRatio,
score_cutoff=75
)
# → "バテスタ" (score: 95.5) マッチ
# 製造社:threshold 80(厳格に — 短い名前は誤マッチリスクが高いため)
製品名はthreshold 75で寛大に、製造社は80で厳格に設定しました。製造社名が短いため低い閾値では誤った名前にマッチされることが多かったためです。タイポが補正されるとそのフィールドの信頼度を0.2上方修正し、補正された結果が検索クエリに安定的に反映されるようにします。
階層的フォールバック検索
TypoCorrectorを経てもOCR結果が完璧でない可能性があります。製品名の前半だけが読まれたり、一部の文字がまだ間違っている可能性があります。単純なExact Matchだけではこのような場合をカバーできないため、1回のクエリ内に様々なレベルのマッチングを階層的に含める戦略を実装しました。
製品名「バテスタ」を例にすると、システムが自動生成する検索パターンは次のとおりです:
"バテスタ" → exact match (boost: 100) ← 完全一致なら最優先
"バテス*" → prefix match (boost: 45) ← "バテスタ", "バテストン"など
"*テスタ" → suffix match (boost: 45) ← "バテスタ", "マステスタ"など
"テス*" → prefix match (boost: 40) ← より短いprefix
"*スタ" → suffix match (boost: 40) ← より短いsuffix
ここに登録番号(boost 80)、製造社(boost 30)、品目名(boost 20)など他のフィールドのマッチングも一緒に組み合わされます。これらのパターンが1つのbool shouldクエリにまとめられてOpenSearchに単一のAPI呼び出しで送信されます:
search_query = {
"bool": {
"should": [
{"term": {"trdmk_nm.keyword": {"value": "バテスタ", "boost": 100}}},
{"wildcard": {"trdmk_nm.keyword": {"value": "バテス*", "boost": 45}}},
{"wildcard": {"trdmk_nm.keyword": {"value": "*テスタ", "boost": 45}}},
{"wildcard": {"trdmk_nm.keyword": {"value": "テス*", "boost": 40}}},
{"wildcard": {"trdmk_nm.keyword": {"value": "*スタ", "boost": 40}}},
{"term": {"reg_no.keyword": {"value": "46-除草-546", "boost": 80}}},
{"match": {"mfr_nm": {"query": "ファームハンノン", "boost": 30}}}
],
"minimum_should_match": 1
}
}
boost値の設計根拠はシンプルです。製品名完全一致(100)が最も確実な識別子であり、登録番号(80)は固有識別番号なので一致すればほぼ確実です。wildcardはbase 50から減った文字数×5を減算して(50 - (len(product_name) - len(prefix)) * 5)、精度が落ちるほどboostが段階的に下がるよう設計しました。製造社(30)と品目名(20)は補助情報としてのみ活用します。
Leading Wildcard(*スタ)検索はインデックス全体をスキャンするためパフォーマンス負担が大きいですが、約4,000種規模の農薬製品群では体感できる応答遅延は発生しませんでした。そのため複雑なインデックスチューニングより検索漏れを防ぐ再現率(Recall)確保を最優先に考慮したトレードオフ戦略を選択しました。このように30件の候補を抽出して次の段階に渡します。
LLM Reranker:最適化された最終判断
OpenSearchが抽出した30件の候補はキーワードマッチング結果なので、意味的・視覚的類似性まで判断するのは難しいです。ここでLLM Rerankerが最終順位を付けます。
速度とコストのための戦略
すべてのリクエストに対してLLMが画像を再分析するのはコストとレイテンシの面で非効率的です。私たちはこれを解決するために2つの最適化戦略を適用しました:
- Candidate Filtering(候補群圧縮):OpenSearch検索結果で製品名が完全一致(Exact Match)する候補が発見されたら、30件全体ではなく該当候補たち(通常1〜2件)だけを抽出してRerankerに渡します。これによりLLMが処理すべきプロンプト長を大幅に減らし、応答速度とコストを最適化しました。
- Precision Reranking(精密検証):圧縮された候補群に対しては元の画像と共にマルチモーダルリランキングを実行します。これは同じ製品名でも剤型(粒剤/水和剤)や容量が異なる微細な違いを最終的に区別するためです。不必要な演算は減らしつつ、精度は妥協しない戦略です。
prompt = f"""抽出された情報と最も一致する候補を見つけてスコアを付けてください。
抽出情報:
製品名:突撃隊 / 製造社:慶農(株)/ 登録番号:52-除草-178
候補製品:
0. 突撃隊(製造社:慶農(株)、登録番号:52-除草-178、成分:ベンタゾン粒剤)
1. 突撃隊(製造社:慶農(株)、登録番号:52-除草-179、成分:ベンタゾン水和剤)
2. 攻撃隊(製造社:ファームハンノン、登録番号:46-除草-333、成分:グリホサート)
...
各候補の関連性スコアを配列でのみ返却:[1.00, 0.85, 0.12, ...]
"""
この3段階パイプラインの核心は各段階が前段階の弱点を補完するという点です。Vision LLMが間違ってもTypoCorrectorがキャッチし、TypeCorrectorがキャッチできなくてもフォールバック検索が候補を確保し、候補が複数あってもRerankerが元の画像を再度見て最終判断します。
データパイプライン
検索品質はインデックスデータの品質に直結します。ETLパイプラインはソースMySQLデータを検索に最適化された形態に変換します。
韓国農薬市場の特性上、同じ情報が様々に表記されます。登録番号「46-除草-546」は「第46-除草-546」とも書かれ、「(株)ファームハンノン」は「ファームハンノン」「ファームハンノン(株)」「株式会社ファームハンノン」などで現れます。「殺菌」と「殺菌剤」、ローマ数字「Ⅲ級」とアラビア「3級」も混用されます。ETLでこれらの変形を事前に生成しておけば、どの表記で検索してもマッチングされます。
インデックスには韓国語Nori Tokenizerを適用して形態素単位でトークン化し、同義語拡張(「殺菌」→「殺菌」「殺菌剤」)も実行します。
Blue-Greenデプロイメント
農薬製品データは定期的に更新されます。検索サービスを中断せずにインデックスを更新するため、新しいインデックスを作成してデータをロードした後、Aliasをアトミックにスイッチングするブルーグリーン戦略を使用します:
def switch_alias(self, new_index: str) -> None:
actions = []
current_index = self.get_current_index()
if current_index:
actions.append({"remove": {"index": current_index, "alias": self.alias_name}})
actions.append({"add": {"index": new_index, "alias": self.alias_name}})
# アトミック実行 → スイッチング瞬間もリクエストロスなし
self.client.indices.update_aliases(body={"actions": actions})
以前のインデックス2つを保管して問題発生時に即座にロールバックできます。
AI基盤統合運営プラットフォーム構築
3つのサービス(Vision API、ETL Pipeline、Console)を効率的に運営するため、Next.js 15基盤の統合管理コンソール(Mega Dev Console)を自社開発しました。単にAPI呼び出しを助けるツールを超えて、AIを活用した運営自動化機能も一緒に実装しました。

実際に撮影した農薬製品(サファイア)— この画像をAPIにアップロードして製品情報を自動抽出
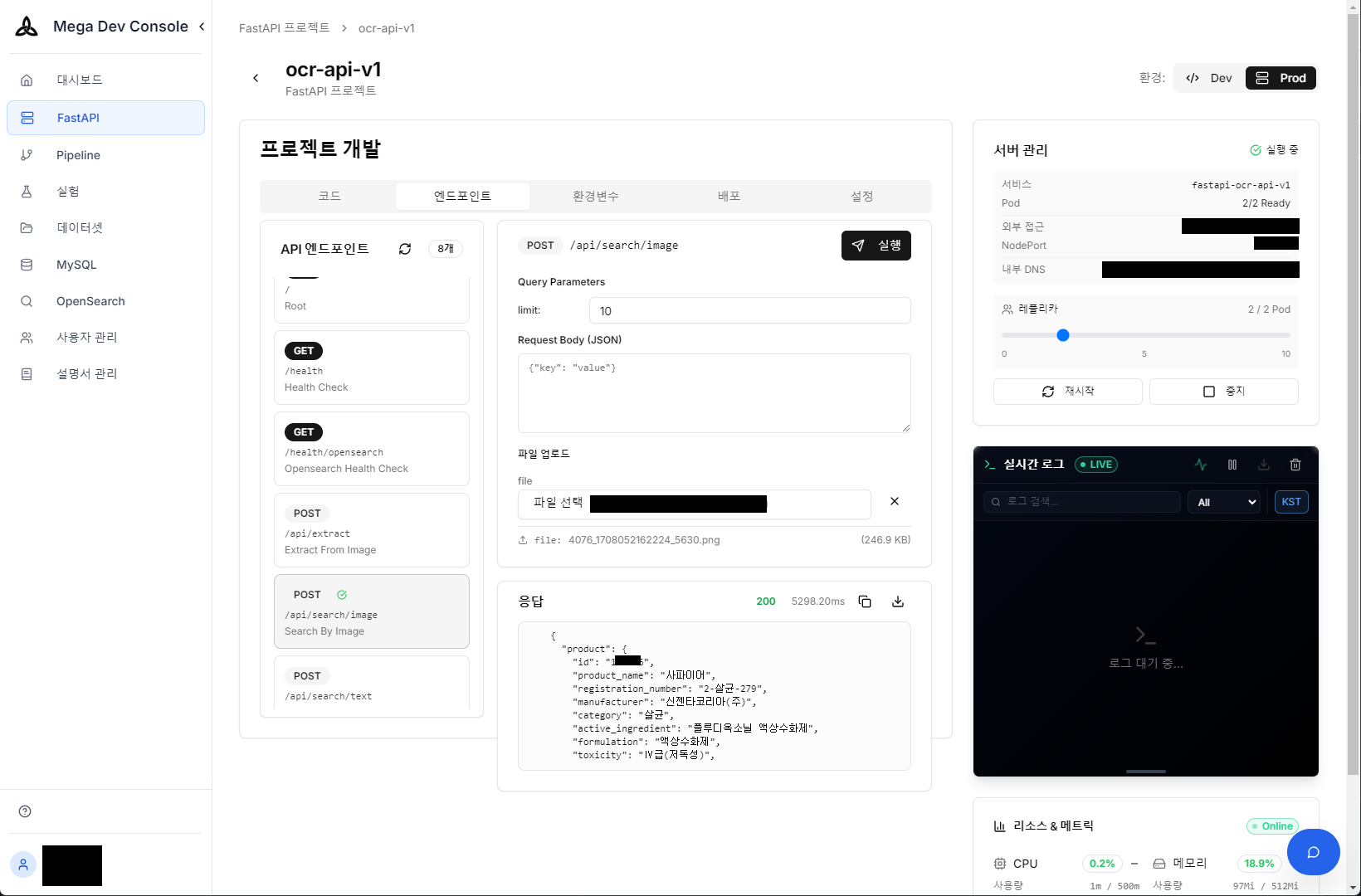
Vision APIリアルタイムテスト — 画像アップロード後、抽出された製品情報と信頼度(JSON)を即座に確認
特にAIを活用した生産性ツールが開発チームの運営負担を大きく軽減しました。
1. 対話型クエリ生成(Text-to-SQL/DSL)
複雑なOpenSearch DSLやMySQL SQLを直接書く必要がありません。「サファイアの数は全部で何個あり、どのように分布していますか?」と自然言語で質問すると、AIがDBスキーマを理解して最適化されたクエリ(SQLまたはDSL)を生成し、実行結果まで即座に表示します。
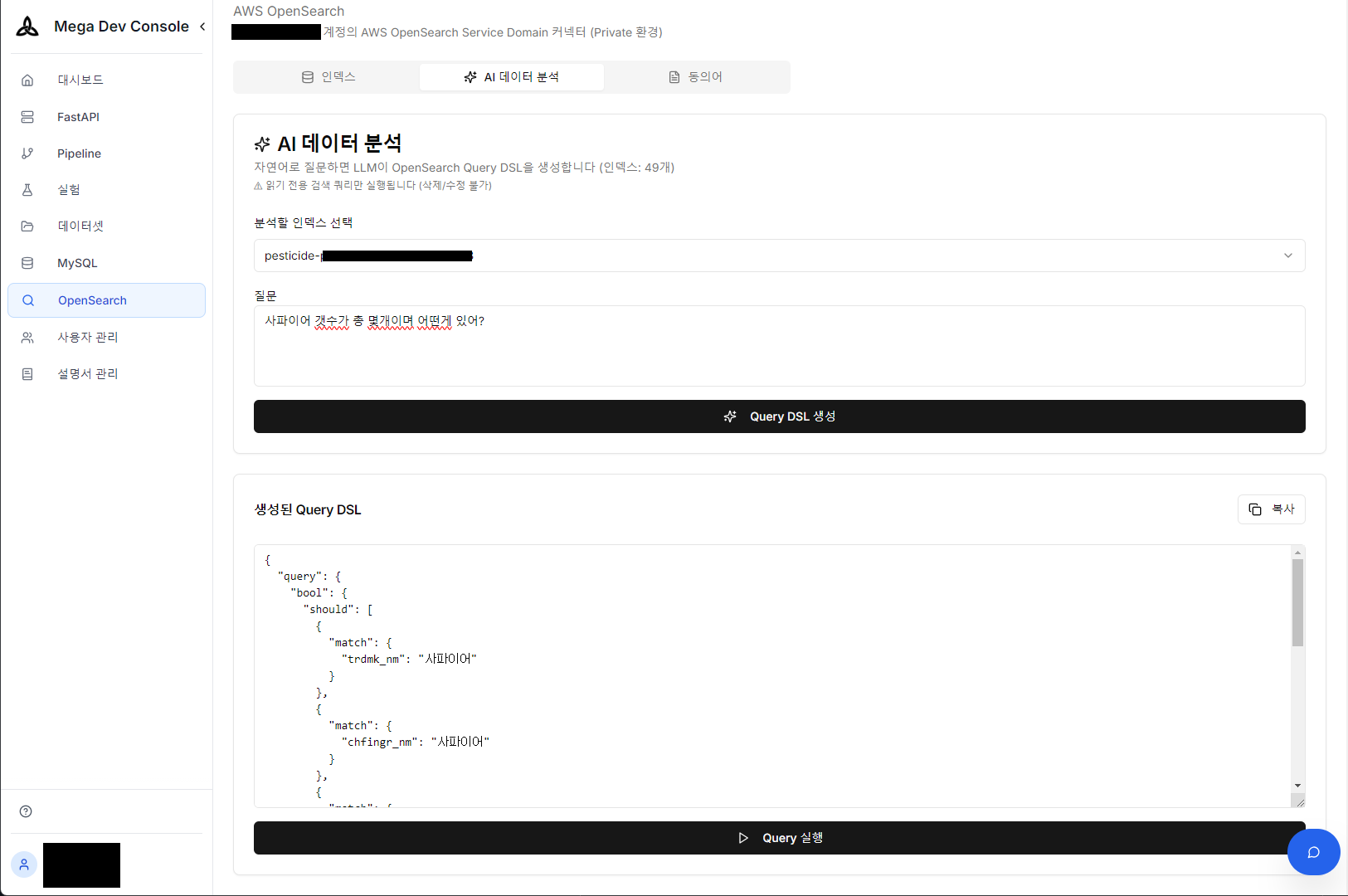
自然言語質問 → OpenSearch Query DSL自動生成
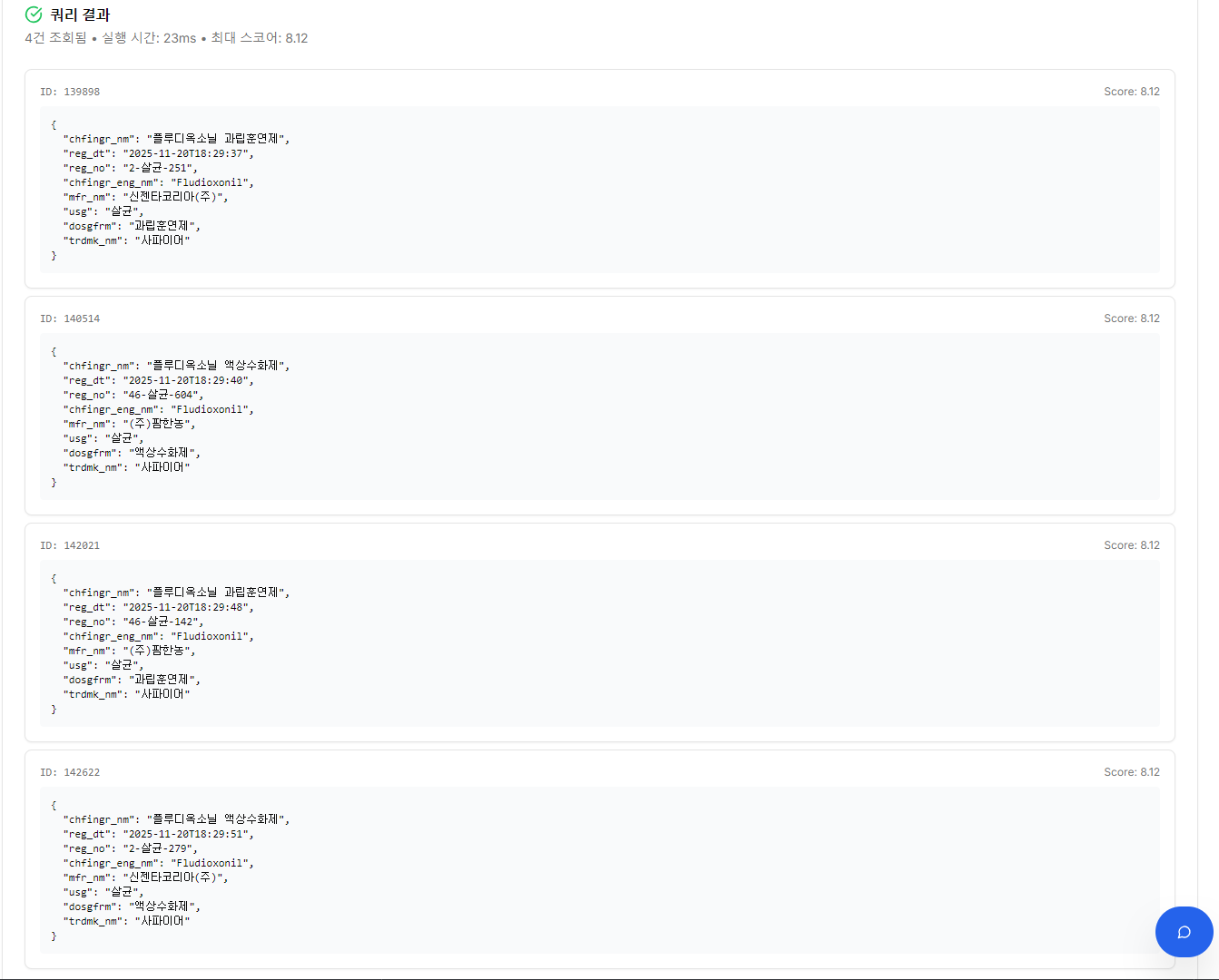
生成されたDSL実行結果 —「サファイア」製品4件照会
2. AIメタデータ自動生成
数千枚の製品画像に一つ一つメタデータを入力するのは相当な時間とコストがかかる大変な作業です。AIプロンプトビルダーを通じて画像から製品名、用途、画像品質などのメタデータ草案を自動抽出しDBにタグ付けして、学習/検証用データセット構築過程を画期的に短縮しました。
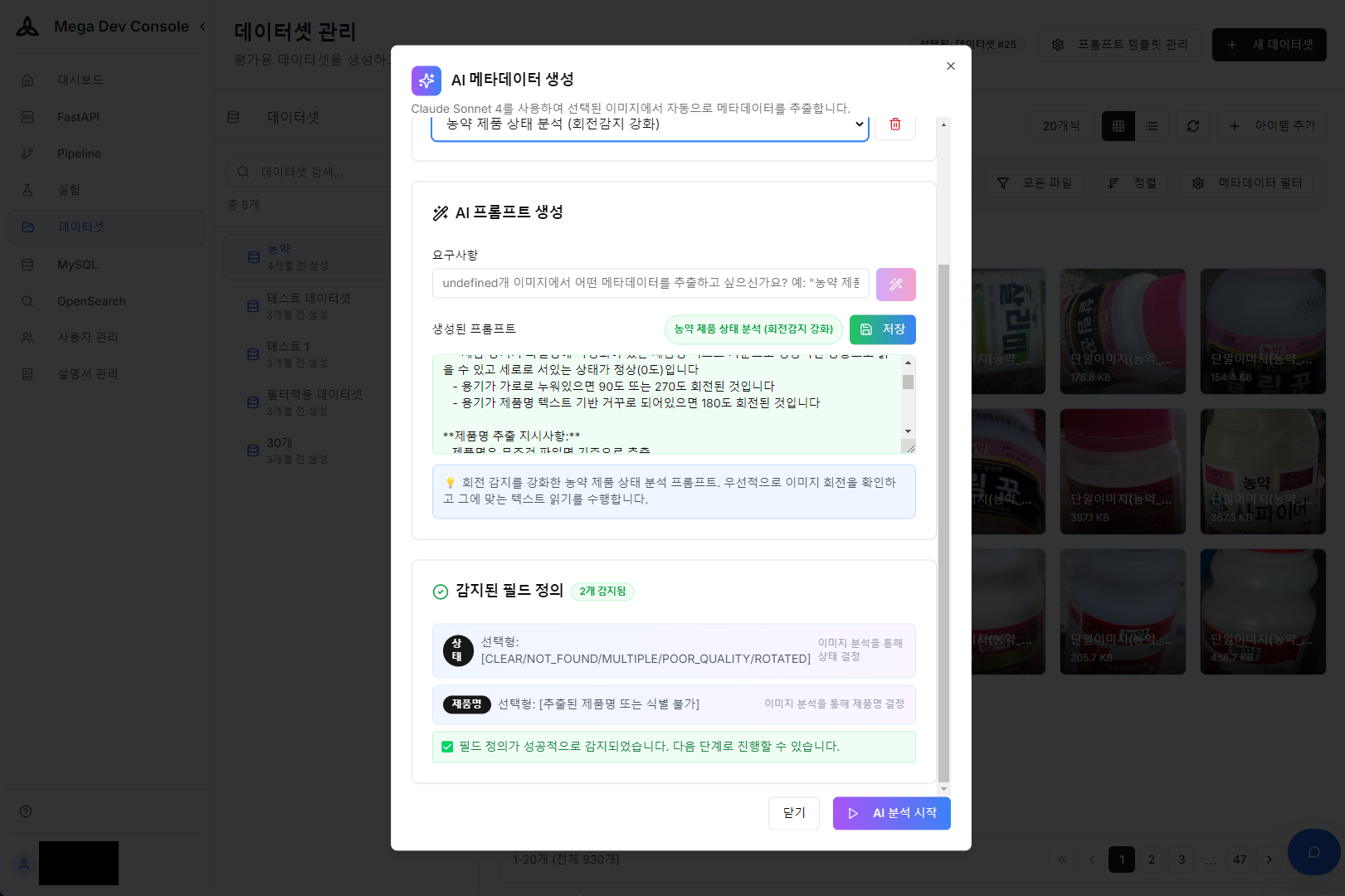
AIプロンプトビルダーを活用したメタデータ抽出プロンプト設定
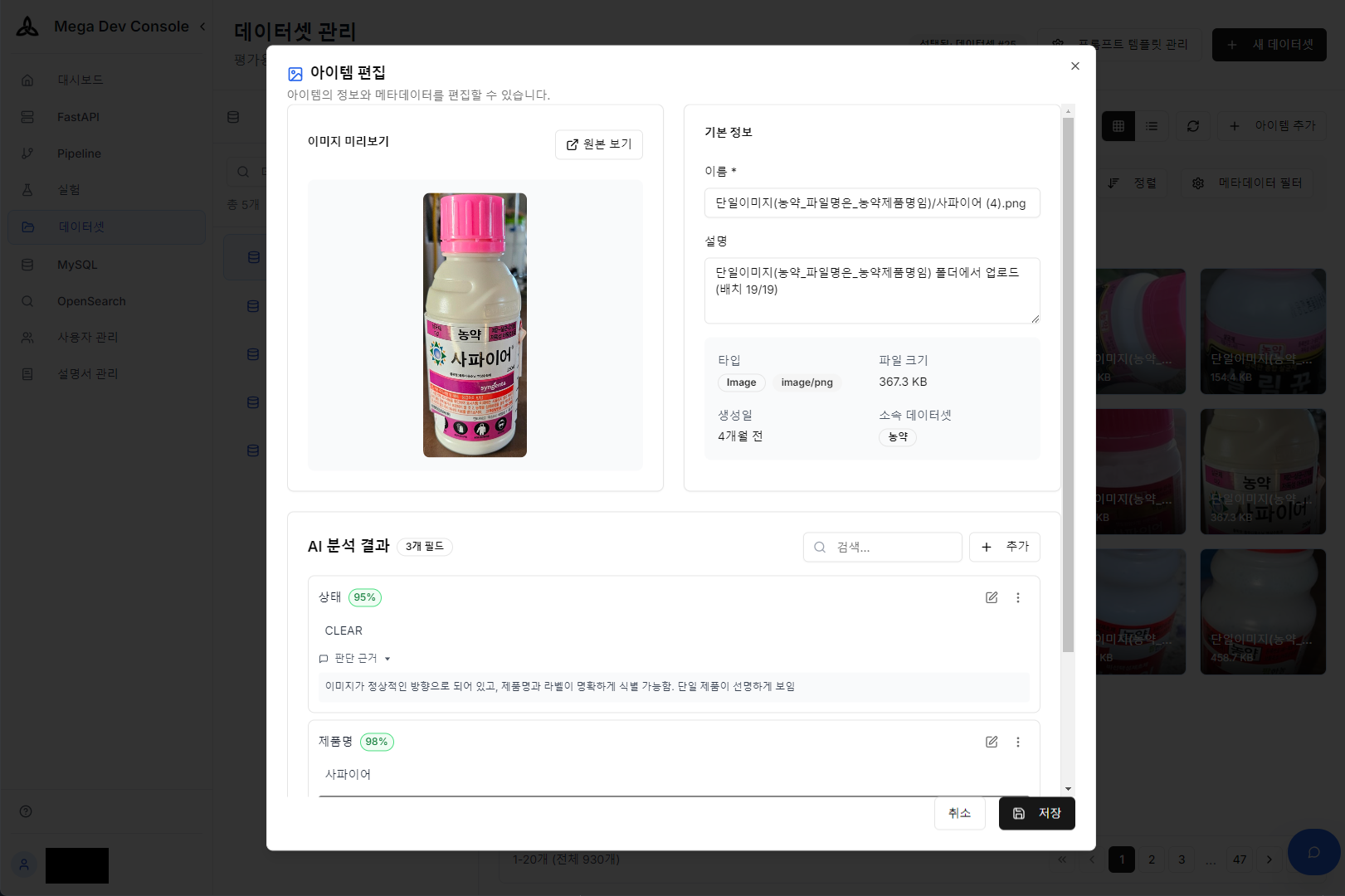
AI分析結果 — 製品画像から自動抽出されたメタデータ確認
3. 自然言語基盤パイプラインスケジューリング
ETLパイプライン運営で最も煩わしいことの1つがCron設定です。「四半期ごとに深夜3時に実行して」のような日常的な言語で入力すると、AIが複雑なCron式を正確に生成してスケジュールに反映します。オペレーターがCron文法を覚える必要がない「ゼロコンフィグレーション」環境を実現しました。
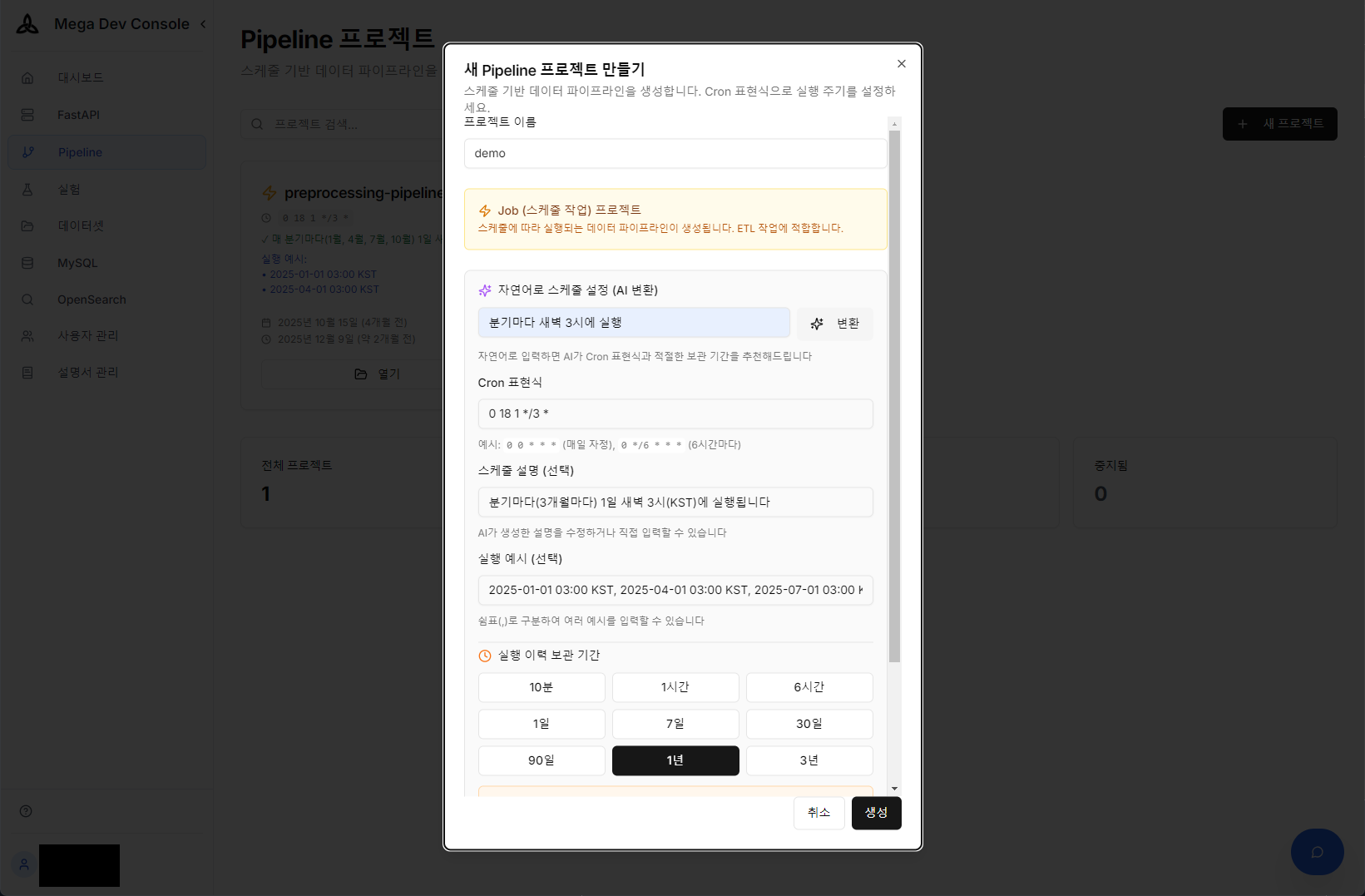
AIを活用した自然言語 → Cron式自動変換およびパイプラインスケジュール設定
4. OCR実験室
バッチ画像に対してOCR精度を定量的に測定する実験室を構築しました。モデルやプロンプトが変更されるたびに大量のテストセットを実行し、正解データと比較して性能変化を即座に検証します。
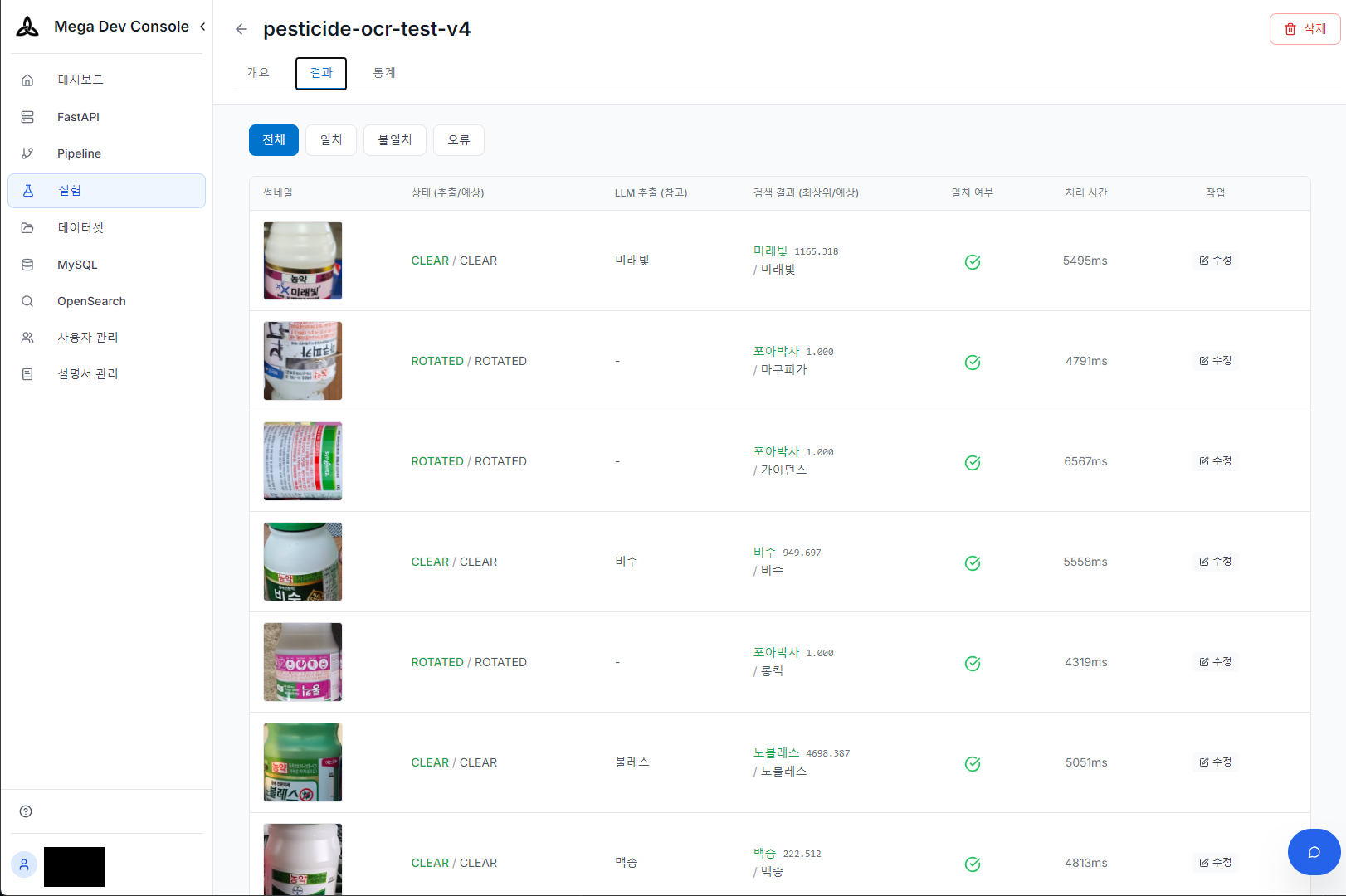
OCR実験結果 — 様々な撮影条件(正常/回転)での抽出・検索・一致可否確認
技術的選択
Claude Haiku 4.5 vs Claude Sonnet 4.5:Vision LLMとReranker両方ともClaude Haiku 4.5を選択しました。Sonnet 4.5の方が精度は高いですが、農薬ラベル認識でHaikuはほとんどの一般的な撮影条件で製品名を正確に抽出しました。応答時間はHaikuが1〜3秒、Sonnetが3〜8秒でコスト差も大きいです。核心は、TypeCorrectorとRerankerがモデルの限界を補完する構造なので個別モデルの精度にあまり依存しないという点です。
OCRアンサンブル試行と最適化:初期には認識率最大化のため専門OCRエンジンの結果をVision LLMにヒントとして提供する方式を検討しました。
- Upstage Document OCR:認識率は卓越していましたがAPIコスト問題で除外されました。
- EasyOCR:韓国語認識は良好でしたが、全体パイプラインレイテンシが5〜10秒以上かかりモバイルUXに不適合でした。
- Tesseract:速度は速かったですが、デザインされたフォントが多い農薬ラベル特性上、認識率が著しく低かったです。
最終的に外部OCRなしでVision LLM単独で使用しつつ、「最も大きいテキスト」のような視覚的手がかりをプロンプトに注入するだけで目標とした認識品質と平均5秒前後の応答速度を達成できました。コードでは環境変数1つでSonnet切り替えが可能にしておきました。
キーワード検索 vs ベクトル検索:農薬製品名は固有名詞中心で、登録番号(46-除草-546)のような識別子はベクトル空間で意味のある距離を持ちません。意味的類似度より文字列類似度が重要なドメインなので、キーワード検索(BM25)をデフォルトとして使用しOCRエラー対策用としてワイルドカードフォールバックを補助的に置きました。ベクトル検索(Titan Embed Text v2)もテストしましたが、製品名と登録番号の正確なマッチングがより重要だと判断し、最終的には無効化しました。
おわりに
このプロジェクトで最も重要な教訓は、Vision LLMは万能ではないという前提の上にシステムを設計すべきということです。
実際のテストでVision LLMはぼやけたりデザインフォントが強いラベルで製品名を間違って読む場合が少なくありませんでした。しかし1〜2文字レベルのエラー —「カネマイト」を「ガネマイト」と、「ダイセン45」を「ダイセンM45」と — はTypeCorrectorとフォールバック検索がほとんど補正し、LLM単独対比で意味のある精度向上を確認しました。一方、製品名が原形を認識できないほど激しく誤認識された場合はシステム全体が失敗し、これは今後プロンプト改善と画像前処理で解決すべき課題です。
ベクトル検索(Embedding)がタイポ問題を一部解決してくれると期待できますが、実際には「バテスタ」と「バテスダ」のような固有名詞の微細な違いがベクトル空間で検索可能なレベルで近くマッピングされない限界がありました。結局キーワード検索をベースにしつつ、TypeCorrectorからRerankerにつながる多重補完構造がOCRとキーワード検索の技術的隙間を埋める核心でした。
モデルの完璧さに依存するよりシステムが誤差をどう回復し補完するかに集中した設計が、性能、コスト、そしてユーザーエクスペリエンスの間の最適点を見つける鍵となりました。
