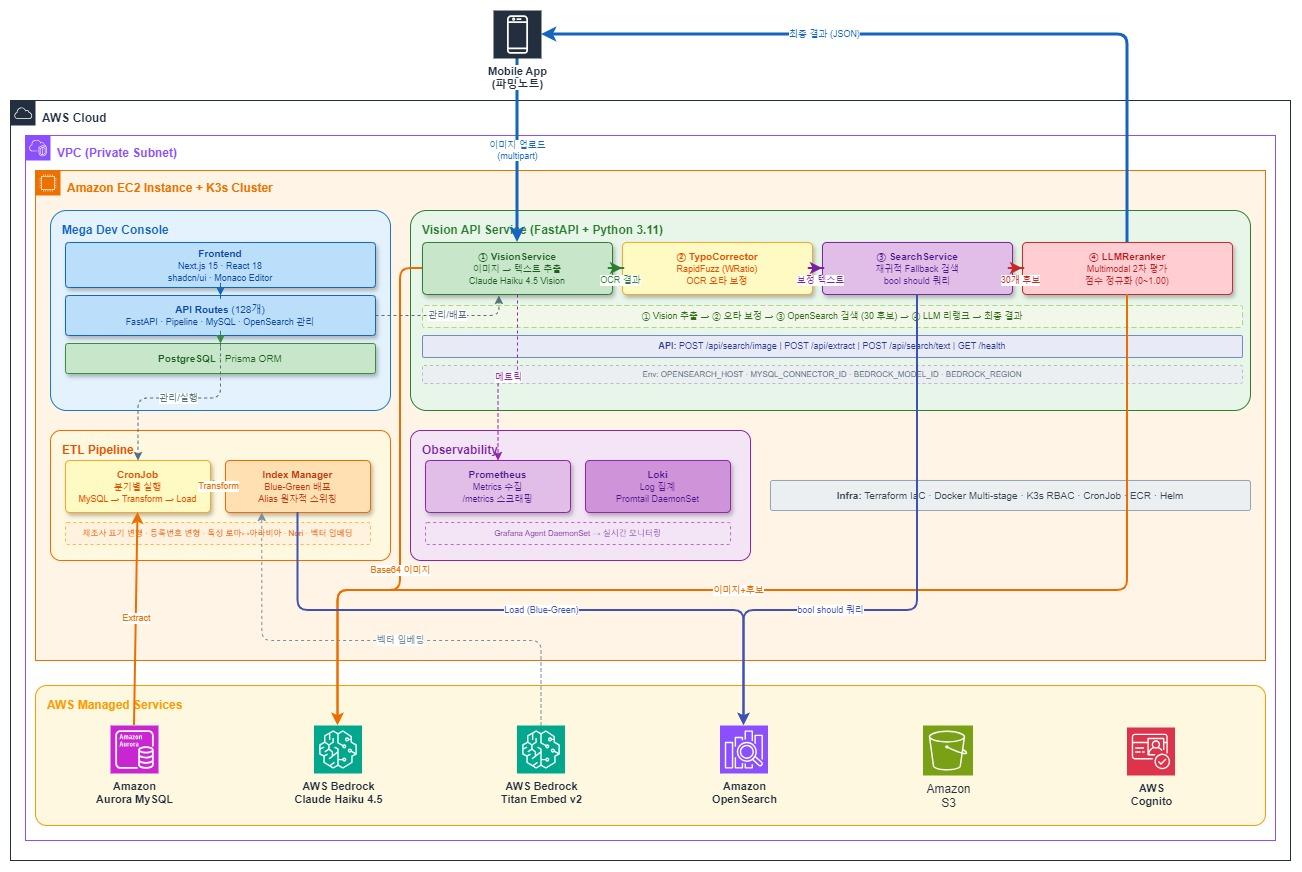
Cutting Output Tokens by 90% and Latency by 87% with Index References in LLM-Based PDF Chunking
TL;DR: Just ask the LLM “from where to where,” and let the server retrieve the text directly. Measured on 3 pages: 90% fewer output tokens, 87% lower latency, 61% cost savings. Background: From Docling to PyMuPDF + VLM While building an AI system for architecture regulation review, we needed to split architecture notice/guideline PDFs into semantically meaningful chunks. These chunks serve as retrieval units in a RAG pipeline. We initially used IBM’s Docling, which uses OCR models to analyze document structure before chunking. However, we ran into two problems: ...