1. Evaluation Overview
Objective: Select embedding models optimized for Korean statutes and ordinance search (RAG) systems
Evaluation Dataset
- KCL-MCQA (Korean Canonical Legal Benchmark)
- 282 questions, 867 case law documents (expert-tagged Ground Truth)
Rationale for Data Selection
- Currently, no public benchmark dataset exists for Korean statutes/ordinances
- KCL-MCQA is the only verified Korean search evaluation dataset in the legal domain
- Case law and statutes/ordinances share identical legal terminology and writing style, enabling similar embedding performance expectations
- Re-evaluation recommended when statute/ordinance-specific evaluation datasets are built
Evaluation Environment
- Search Engine: PostgreSQL pgvector with HNSW index
- Evaluation Metrics: Recall@5, Precision@5, MRR, NDCG@5
2. Comparison Models
| Model | Provider | Dimension | Characteristics |
|---|---|---|---|
| Amazon Titan V2 | AWS Bedrock | 1024 | AWS native, cost-effective |
| Cohere Embed V4 | AWS Bedrock | 1536 | Multilingual specialized, high-performance |
| KURE-v1 | HuggingFace (requires SageMaker hosting) | 1024 | Korean-specialized open-source |
3. Evaluation Metrics Explanation
Recall@K (Recall) ⭐⭐⭐
Definition: Proportion of relevant documents included in top K results
Formula: (Number of relevant documents found in top K) / (Total number of relevant documents)
Interpretation
- Higher values mean better identification of relevant documents without omissions
- Most important metric for legal search (prevents missing critical documents)
Example: If there are 5 relevant cases but only 3 appear in top 5 results → Recall@5 = 60%
Precision@K (Precision) ⭐
Definition: Proportion of relevant documents among top K results
Formula: (Number of relevant documents found in top K) / K
Interpretation
- Higher values mean fewer unnecessary documents in search results
- Reduces the number of documents users need to review
Example: If 3 out of top 5 results are actually relevant → Precision@5 = 60%
MRR (Mean Reciprocal Rank) ⭐⭐
Definition: Average of the reciprocal ranks where the first relevant document appears
Formula: 1 / (Rank of first relevant document)
Interpretation
- Higher values indicate relevant documents appear higher in rankings
- Measures the quality of the first result users see
Example
- First result is relevant → MRR = 1.0
- Third result is the first relevant one → MRR = 0.33
NDCG@K (Normalized Discounted Cumulative Gain) ⭐⭐
Definition: Comprehensive search quality score considering ranking positions
Interpretation
- Higher scores when relevant documents rank higher
- Evaluates “where” documents appear, not just “whether” they appear
- Values between 0-1, with values closer to 1 indicating ideal ranking
Example: Documents ranked 1st and 2nd get high scores; documents ranked 8th and 9th get low scores
4. Evaluation Results
4.1 Performance Metrics Comparison
| Model | Recall@5 | Precision@5 | MRR | NDCG@5 | Rank |
|---|---|---|---|---|---|
| Cohere Embed V4 | 55.60% | 34.54% | 69.45% | 55.14% | 1st |
| KURE-v1 | 47.15% | 29.36% | 63.57% | 47.02% | 2nd |
| Amazon Titan V2 | 40.09% | 24.18% | 59.00% | 40.68% | 3rd |
4.2 Performance Comparison Chart
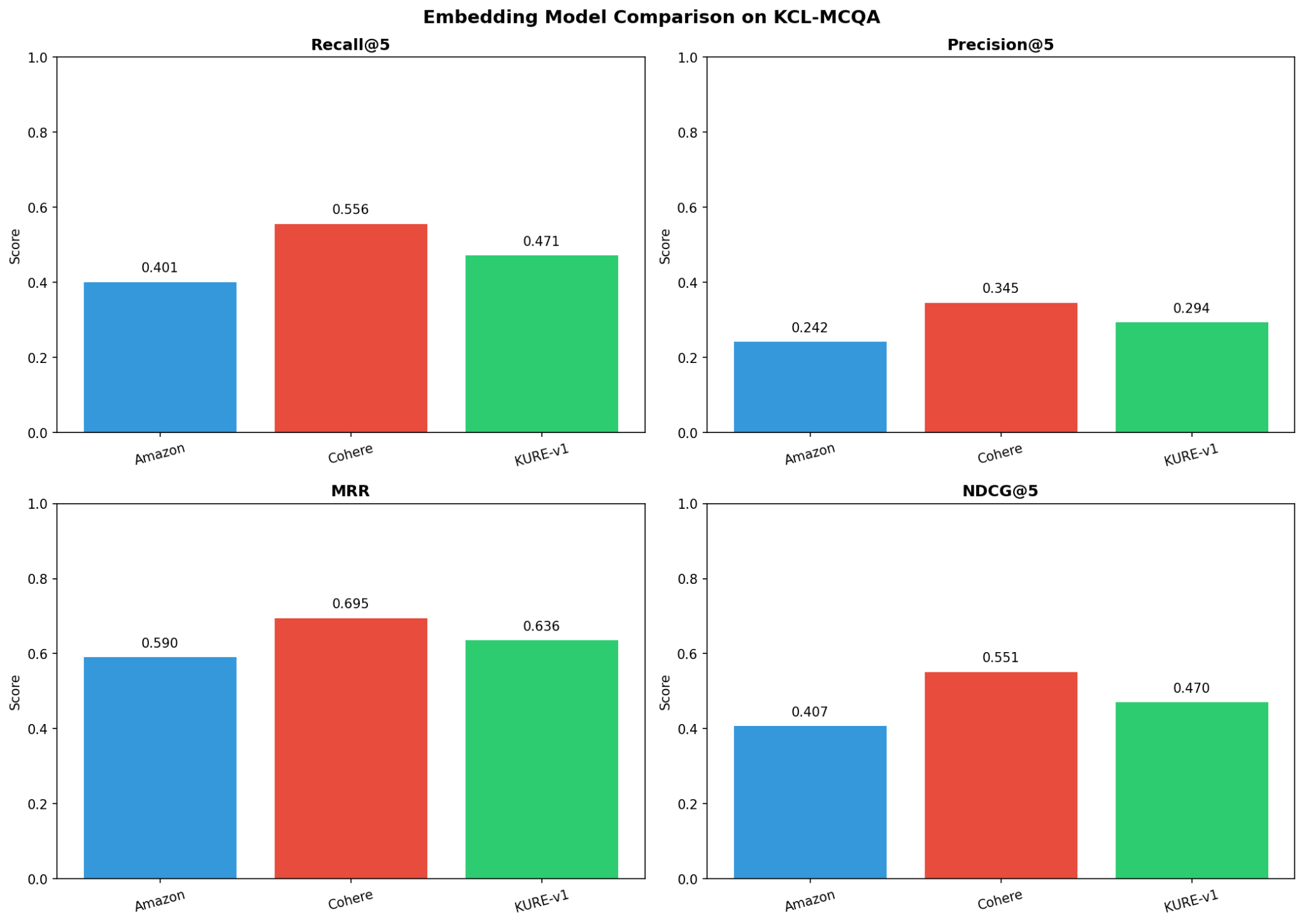
Figure: Performance metrics comparison of three models
4.3 Performance Difference Analysis
| Comparison | Recall Difference | Improvement | MRR Difference | Improvement |
|---|---|---|---|---|
| Cohere vs Titan | +15.5%p | 38.7% | +10.5%p | 17.7% |
| Cohere vs KURE | +8.5%p | 17.9% | +5.9%p | 9.3% |
| KURE vs Titan | +7.1%p | 17.6% | +4.6%p | 7.7% |
4.4 Key Findings
- Cohere Embed V4 ranks first across all metrics
- Korean-specialized KURE-v1 outperforms general-purpose Titan V2, but falls short of Cohere
- MRR differences are smaller than Recall differences → All models find “first results” relatively well
5. Cost Analysis
5.1 Embedding API Costs (Bedrock)
| Model | Price (1K tokens) | Cost for 1,000 documents | Cost for 1M documents |
|---|---|---|---|
| Amazon Titan V2 | $0.00002 | $0.012 | $12.30 |
| Cohere Embed V4 | $0.00012 | $0.060 | $60.00 |
5.2 KURE-v1 Hosting Costs (SageMaker)
KURE-v1 is open-source but requires SageMaker infrastructure for hosting.
| Hosting Method | Memory/Instance | Hourly Cost | Monthly (100k requests) | Notes |
|---|---|---|---|---|
| Serverless | 4GB | ~$0.0000467/sec | $5-10 | Variable cost |
| Real-time | ml.g4dn.xlarge | ~$0.7364/hour | $530 | Fixed cost |
5.3 Monthly Operating Cost Comparison (100k requests basis)
| Model | Hosting Method | Monthly Cost | Management Burden |
|---|---|---|---|
| Titan V2 | Bedrock API | ~$1.23 | None |
| Cohere V4 | Bedrock API | ~$6.00 | None |
| KURE-v1 | SageMaker Serverless | ~$5-10 | Medium (cold start latency) |
| KURE-v1 | SageMaker Real-time | ~$50-100 | High (instance management) |
6. Detailed Model Analysis
6.1 Cohere Embed V4
| Aspect | Details |
|---|---|
| Strengths | - Highest performance (Recall 55.6%) - Excellent Korean legal terminology understanding from multilingual training - Easy operations via Bedrock integration |
| Weaknesses | - About 5x higher cost than Titan |
| Best For | Legal services, B2B services where accuracy is critical |
6.2 KURE-v1 (Korea University)
| Aspect | Details |
|---|---|
| Strengths | - Korean-specialized training - Customizable as open-source - Storage-efficient with 1024 dimensions |
| Weaknesses | - Requires SageMaker hosting (additional infrastructure management) - Serverless cold start latency (several seconds) - Real-time endpoints incur significant costs - 8.5%p lower performance than Cohere |
| Best For | Cases requiring fine-tuning/customization, internal systems (where latency tolerance is acceptable) |
6.3 Amazon Titan V2
| Aspect | Details |
|---|---|
| Strengths | - Most cost-effective - Native Bedrock integration - Minimal operational complexity |
| Weaknesses | - Lowest performance (Recall 40.1%) - Lacks optimization for Korean legal domain |
| Best For | MVP/prototypes, cost-sensitive services, where speed/cost matters more than accuracy |
7. Recommendations
7.1 Final Recommendation
Cohere Embed V4
In legal domains, a 15%p difference in Recall is far more significant than the cost difference.
7.2 Rationale
- Legal Domain Specificity
Missed statutes/ordinances can lead to incorrect legal interpretation.
- Recall 55.6% vs 40.1% = 1.5 additional documents found per 10 queries
- These 1.5 documents could contain critical legal provisions
- Relative Cost Significance
| Item | Cost |
|---|---|
| Additional Cohere cost (monthly, 100k requests) | $4.77 |
| Single legal service retainer fee | Several hundred thousand won+ |
→ From ROI perspective, Cohere cost is negligible
- Operational Convenience
- Infrastructure management unnecessary with Bedrock API
- No SageMaker operational burden compared to KURE-v1
8. Conclusion
Performance Rankings
| Rank | Model | Recall@5 | Characteristics |
|---|---|---|---|
| 1 | Cohere Embed V4 | 55.6% | Highest performance |
| 2 | KURE-v1 | 47.2% | Korean-specialized |
| 3 | Amazon Titan V2 | 40.1% | Cost-effective |
Core Insights
| Perspective | Conclusion |
|---|---|
| Absolute Performance | Cohere V4 superior across all metrics |
| Cost Efficiency | Titan V2 most efficient but sacrifices performance significantly |
| Korean Specialization | KURE-v1 better than Titan but cannot match Cohere |
| Operational Convenience | Bedrock models (Titan, Cohere) more convenient than SageMaker |
Final Conclusion
The core value in legal domains is “reliability.”
Cohere V4’s 55.6% Recall is not perfect, but significantly more trustworthy than Titan V2’s 40.1% or KURE-v1’s 47.2%.
The risk of “missing critical legal provisions” in statute/ordinance search cannot be offset by saving a few dollars monthly.
Therefore, Cohere Embed V4 is strongly recommended.
Appendix: Evaluation Environment
| Item | Details |
|---|---|
| Evaluation Date | January 2026 |
| Dataset | KCL-MCQA (lbox/kcl) |
| Evaluation Queries | 282 |
| Corpus | 867 case law documents (500+ characters) |
| Search Engine | PostgreSQL 16 + pgvector 0.7 |
| Index | HNSW (m=16, ef_construction=64) |
