
250+ Industrial Protocols · Edge-to-Cloud Pipeline · Physical-Level Project Isolation
A real-world Manufacturing Data Engine deployment balancing security and cost trade-offs
Cloud Tech Unit · GCP Delivery SA 3 Yoon Sung-jae | 2026-02-23
Business Background — PINN Model-Based Convergence Data Platform
In manufacturing digital transformation (DX), the biggest hurdle is the “last mile” — securely and seamlessly moving on-site IT and OT data to the cloud.
This article covers a case where, as the cloud infrastructure partner for the Korean government-led “2025 PINN (Physics-Informed Neural Networks) Model Manufacturing Convergence Data Collection and Validation Project,” we built an integrated system on Google Cloud Manufacturing Data Engine (MDE) for heterogeneous data from 8 manufacturing companies.
The initial collection target in the project plan was 185TB, but by building a high-performance pipeline supporting over 250 industrial protocols, we successfully collected a total of 279TB of manufacturing data (time-series sensors, images, video, etc.) — exceeding the target by 150%. This article shares the Architecture Decision Records (ADR) we intensely debated to build that massive data dam.
Problem Definition — Three Dilemmas of OT-IT Convergence
High-quality raw data is essential for successful PINN model training. However, to realize the project’s core goal of “IT-OT convergence,” we first had to understand the nature and differences between data from these two domains.
- IT (Information Technology) Data: Data generated from business systems supporting operations like ERP and MES
- OT (Operational Technology) Data: Data generated from field technologies controlling physical equipment and managing production, such as PLCs and SCADA
We encountered the following practical barriers when bringing these two domains together.
Fragmented Equipment Environments and Protocols (Heterogeneous Environment)
Each of the 8 factories used different equipment. In the IT domain, the databases used by systems like ERP and MES varied, and in the OT domain, each factory had deployed equipment from different manufacturers. To make matters worse, the target data formats ranged from structured data such as CSV, JSON, and Parquet to unstructured data like images (JPG, PNG, BMP) and video (MPG, MP4), making it extremely difficult to establish a standardized collection framework.
Network Bandwidth Limitations and Data Loss Risk (Network Reliability)
The network environment at manufacturing sites was inadequate for transferring large volumes of data to the cloud. External internet connections lacked redundant lines, and sharing existing internal business network lines caused chronic bandwidth shortages. Even during network delays or disconnections, data had to be safely buffered at the edge without loss, and a robust architecture was needed to ensure lossless, in-order transmission to the cloud upon network recovery.
Strict Inter-Company Data Isolation (Strict Multi-Tenancy)
The 8 participating manufacturers could potentially be competitors. While using the “shared resources” of the cloud, achieving physical-level logical isolation that completely eliminated concerns about data cross-contamination was key to the project’s success.
Overall Architecture — Edge-to-Cloud Pipeline
To solve these problems, we adopted Google Cloud’s specialized solutions — MDE (Manufacturing Data Engine) and MC (Manufacturing Connect) — as the core. The overall architecture was designed in 4 layers under the principle of “never impacting field equipment.”
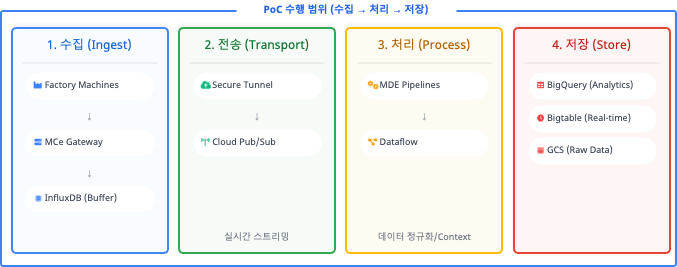
| Layer | Component | Key Role |
|---|---|---|
| Edge | MCe (Manufacturing Connect Edge) | Located within the field network. Supports 250+ protocols. Performs edge local buffering using InfluxDB during network disconnections |
| Transport | Cloud Pub/Sub | High-volume asynchronous streaming handling millions of events per second. Acts as a buffer zone to prevent system crashes during traffic spikes |
| Processing | Cloud Dataflow | Real-time data normalization. Combines sensor values with metadata such as equipment names and line positions (Contextualization) to add business value |
| Storage | BigQuery / Bigtable / GCS | Adopts Lambda Architecture. Distributed storage: BQ for large-scale analytics, BT for real-time queries, Cloud Storage for large files |
Key Decision — Trade-off Between Security and Cost
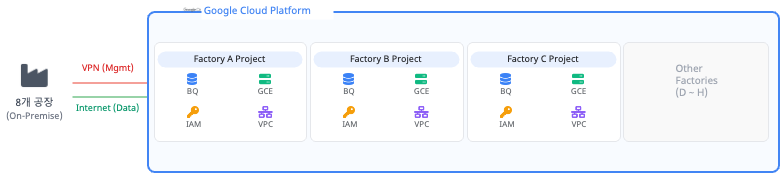
The most challenging consideration as a cloud architect was “how to design the multi-tenancy environment.” Since the collection targets were 8 different (and potentially competing) companies, an architectural decision on the level of data isolation was required.
Alternative A: Dataset-level Isolation Within a Single Project
This approach centralizes all factory data pipelines (Pub/Sub, Dataflow, etc.) within a single unified GCP project and creates “per-factory datasets” only at the final storage layer (BigQuery) for logical isolation.
- Pros: All 8 factories share infrastructure resources, preventing computing resource waste and making this highly favorable for cost optimization (Cost Efficiency). Additionally, pipeline monitoring and deployment from a single point provides high operational management efficiency.
- Cons: Since data from multiple companies passes through the same memory (Dataflow workers) and queues (Pub/Sub), there is a potential security risk of data cross-contamination or exposure from minor IAM permission misconfigurations or pipeline code errors.
Alternative B: Project-level Isolation With Independent Projects Per Factory
This approach assigns a completely independent GCP project to each of the 8 factories. Each factory gets its own VPC network, Pub/Sub, Dataflow workers, and BigQuery instances, physically blocking all data flows from collection to storage.
- Pros: Boundaries are perfectly separated at the project level, eliminating any possibility of data mixing and maximizing security and data independence. Project-level IAM permissions provide clear access control, and billing can be cleanly separated per project for transparency.
- Cons: Running identical infrastructure (VPC, logging, pipelines, etc.) 8 times significantly increases TCO. Idle resources arise from dedicated Dataflow workers allocated even to factories with low data volumes, and individually patching and monitoring 8 environments greatly increases operational complexity.
Architect’s Note: During the initial design phase, the allure of scalability and cost efficiency (Alternative A) was strong. However, given the nature of a government validation project, completely eliminating participating companies’ security concerns (data leakage between competitors) was critical to overall success. Ultimately, we chose Project-level Isolation (Alternative B), which provides physical-level isolation, even at the significant expense of cost efficiency and operational convenience.
Network Security — Dual-Track Transmission
To respect the closed nature of manufacturing (OT) networks, we split network traffic into two tracks.
- Management Traffic: Firmware updates and configuration management deployed from the MC central server to the edge (MCe) are controlled exclusively through VPN (Private) tunnels.
- Data Traffic: Terabyte-scale sensor data cannot be handled by VPN bandwidth, so it was designed to be transmitted directly to GCP Pub/Sub endpoints via TLS-encrypted public internet lines.
Key Lessons
The Cost of Perfect Isolation and the Need for Cost Optimization
Thorough project isolation was excellent from a security standpoint, but duplicate Dataflow workers and monitoring environments were created for each factory, resulting in significant idle resources. In future project expansions, a hybrid approach based on Shared VPC — sharing infrastructure while completely isolating data logically — should be adopted.
The Importance of Data Governance Standardization
Even for the same “temperature” data, Factory A used temp_1 while Factory B used temperature_val. For integrated PINN model training, establishing schema standardization and enterprise-wide metadata dictionary rulesets at the pre-collection stage is critical.
Next Steps for AI and Analytics
This PoC essentially opened a powerful “highway” for convergence data to flow safely. In the upcoming main project, the collected data will be used for visualization through Looker dashboards and development of predictive maintenance PINN models on Vertex AI — moving toward the true business value creation stage.
